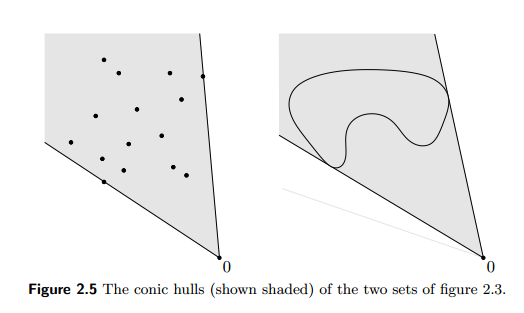
Jensen's inequality¶
- Funciton $f$ is convex if and only if
$$
f(\sum_{i=1}^m\mathbf{x}_i) \le \sum_{i=1}^m\alpha_i f(\mathbf{x}_i), \quad \forall \mathbf{x}_1, \dotsc, \mathbf{x}_m, ~\forall\alpha_i \ge 0, ~ \sum_{i=1}^m \alpha_i=1.
$$
First-order condition (supporting hyperplane inequality)¶
If $f$ is differentiable (i.e., its gradient $\nabla f$ exists at each point in $\text{dom}f$, which is open), then $f$ is convex if and only if $\text{dom} f$ is convex and
$$
f(\mathbf{y}) \ge f(\mathbf{x}) + \langle \nabla f(\mathbf{x}), \mathbf{y}-\mathbf{x} \rangle
$$
for all $\mathbf{x}, \mathbf{y} \in \text{dom}f$.
Second-order condition¶
- If $f$ is twice differentiable (i.e., its Hessian $\nabla^2 f$ exists at each point in $\text{dom}f$, which is open), then $f$ is convex if and only if $\text{dom} f$ is convex and its Hessian is positive semidefinite:, i.e,
$$
\nabla^2 f(\mathbf{x}) \succeq \mathbf{0}
$$
for all $\mathbf{x} \in \text{dom} f$.
- If $\nabla^2 f(\mathbf{x}) \succ \mathbf{0}$, then $f$ is strictly convex.
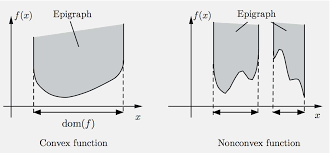
Epigraph¶
The epigraph of a function $f$ is the set
$$
\text{epi}f = \{(\mathbf{x}, t): \mathbf{x}\in\text{dom}f,~ f(\mathbf{x}) \le t \}.
$$
A function $f$ is convex if and only if $\text{epi}f$ is convex.
If $(\mathbf{y}, t)\in\text{epi}f$, then from the supporting hyperplance inequality,
$$
t \ge f(\mathbf{y}) \ge f(\mathbf{x}) + \langle \nabla f(\mathbf{x}), \mathbf{y} - \mathbf{x} \rangle
$$
or
$$
\left\langle (\nabla f(\mathbf{x}), -1), (\mathbf{y}, t) - (\mathbf{x}, f(\mathbf{x})) \right\rangle \le 0.
$$
This means that the hyperplane defined by $(\nabla f(\mathbf{x}),−1)$ supports $\text{epi}f$ at the
boundary point $(\mathbf{x},f(\mathbf{x}))$:

An extended-value function $f$ is called closed if $\text{epi}f$ is closed.
Separating hyperplane theorem¶
Let $A$ and $B$ be two disjoint nonempty convex subsets of $\mathbb{R}^n$. Then there exist a nonzero vector $\mathbf{v}$ and a real number $c$ such that
$$
\mathbf{a}^T\mathbf{v} \le c \le \mathbf{b}^T\mathbf{v},
\quad
\forall\mathbf{a} \in A,~
\forall\mathbf{b} \in B
.
$$
That is, the hyperplane $\{\mathbf{x}\in\mathbb{R}^n: \mathbf{x}^T\mathbf{v} = c\}$ normal to $\mathbf{v}$ separates $A$ and $B$.
If in addition both $A$ and $B$ are closed and one of them is bounded, then the separation is strict, i.e., there exist a nonzero vector $\mathbf{v}$ and real numbers $c_1$ and $c_2$ such that
$$
\mathbf{a}^T\mathbf{v} < c_1 < c_2 < \mathbf{b}^T\mathbf{v},
\quad
\forall\mathbf{a} \in A,~
\forall\mathbf{b} \in B
.
$$
Thus there exists a hyperplane that strictly separates $(y, \zeta)$ and $\text{epi}\varphi$ in the above plot if $\varphi$ is closed. (why?)
Sublevel sets¶
$\alpha$-sublevel set of an extended-value function $f$ is
$$
S_{\alpha} = \{\mathbf{x}\in\text{dom}f : f(\mathbf{x}) \le \alpha \}.
$$
If $f$ is convex, then $S_{\alpha}$ is convex for all $\alpha$.
- Converse is not true: $f(x)=-e^{x}$.
Further if $f$ is continuous, then all sublevel sets are closed.