Julia Version 1.9.3
Commit bed2cd540a1 (2023-08-24 14:43 UTC)
Build Info:
Official https://julialang.org/ release
Platform Info:
OS: macOS (x86_64-apple-darwin22.4.0)
CPU: 8 × Intel(R) Core(TM) i5-8279U CPU @ 2.40GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.6 (ORCJIT, skylake)
Threads: 2 on 8 virtual coresA Brief Introduction to Julia
Advanced Statistical Computing
Joong-Ho Won
Seoul National University
September 2023
A quick CS101
What is a computer?
Modern computer can be defined as
machines that store and manipulate information under the control of a changeable program.
Two key elements:
- Machines for manipulating information
- Control by a changeable program
What is a computer program?
A detailed, step-by-step set of instructions telling a computer what to do.
If we change the program, the computer performs a different set of actions or a different task.
The machine stays the same, but the program changes!
Programs are executed, or carried out.
- Software (programs) rule the hardware (the physical machine).
- The process of creating this software is called programming.
Algorithm
One way to show a particular problem can be solved is to actually design a solution.
This is done by developing an algorithm, a step-by-step process for achieving the desired result.
Hardware Basics
- The central processing unit (CPU) is the “brain” of a computer.
- The CPU carries out all the basic operations on the data.
- Examples: simple arithmetic operations, testing to see if two numbers are equal.
- Memory stores programs and data.
- CPU can only directly access information stored in main memory (RAM or Random Access Memory).
- Main memory is fast, but volatile, i.e. when the power is interrupted, the contents of memory are lost.
- Secondary memory provides more permanent storage: magnetic (hard drive, floppy), optical (CD, DVD), flash (SSD)
- I/O
- Input devices: Information is passed to the computer through keyboards, mice, etc.
- Output devices: Processed information is presented to the user through the monitor, printer, etc.
- Fetch-Execute Cycle
- First instruction retrieved from memory
- Decode the instruction to see what it represents
- Appropriate action carried out.
- Next instruction fetched, decoded, and executed.
Programming Languages
Natural language has ambiguity and imprecision problems when used to describe complex algorithms.
- Programs are expressed in an unambiguous, precise way using programming languages.
- Every structure in programming language has a precise form, called its syntax.
- Every structure in programming language has a precise meaning, called its semantics.
- Programmers will often refer to their program as computer code.
- Process of writing an algorithm in a programming language often called coding.
Low-level Languages
Computer hardware can only understand a very low level language known as machine language.
- Example: add two numbers in ARM assembly
@ Load the first number in memory address 0x2021 into register R0
ldr r0, 0x2021
ldr r0, [r0]
@ Load the second number in memory address 0x2022 into register R1
ldr r1, 0x2022
ldr r1, [r1]
@ Add the numbers in R0 and R1 and store the result in R2
add r2, r0, r1
@ Store the result in memory address 0x2023
ldr r3, 0x2023
str r2, [r3]In reality, these low-level instructions are represented in binary (1’s and 0’s)
High-level Languages
Designed to be used and understood by humans
- This needs to be translated into the machine language that the computer can execute.
- Compilers convert programs written in a high-level language (source code) into the target machine language.
- Fortran, C/C++, Java, Go, Swift
- Interpreters simulate a computer that understands a high-level language.
- The source code is not translated into machine language all at once.
- An interpreter analyzes and executes the source code instruction by instruction.
- Interpreted languages are part of a more flexible programming environment since they can be developed and run interactively, at the expense of slower execution time than compiled languages.
- Commandline shells, Lisp, R, Python, Julia
Dynamic Languages
A dynamic programming language is a class of high-level programming languages, which at runtime can change the behavior of the program by adding new code.
- Also called a scripting language
Most dynamic languages are interpreted languages, providing an interactive read-eval-print loop (REPL).
Traditional interpreters parse the source code into an intermediate representation (IR) such as an abstract syntax tree (AST) and execute predetermined routines.
Just-in-time Compilation
- Modern interpreters compiles the parsed IR to native machine code at runtime. If the same part of the source code (e.g., function) is executed again, then the compiled native code is executed. This technique is called just-in-time (JIT) compilation.
- For subsequent uses (e.g., calling the function within a loop), the speedup is significant.
- More and more interpreter languages are adopting JIT technology: R (version 3.4+), MATLAB (R2015b+), Python (PyPy), Julia, …
- Distinction between complier and interpreter languages is getting blurred due to improved computation capabilities of the modern hardware and advanced compiler techniques.
Julia
What’s Julia?
Julia is a high-level, high-performance dynamic programming language for technical computing, with syntax that is familiar to users of other technical computing environments.
- Project started in 2009. First public release in 2012
- Creators: Jeff Bezanson, Alan Edelman, Stefan Karpinski, Viral Shah
- First major release: v1.0 on Aug 8, 2018
- Current stable release: v1.9.3 (August 24, 2023)
Aim to solve the notorious two language problem: Prototype code goes into high-level languages like R/Python, production code goes into low-level language like C/C++.
Julia aims to:
Walks like Python. Runs like C.
- Write high-level, abstract code that closely resembles mathematical formulas
- yet produces fast, low-level machine code that has traditionally only been generated by static languages.

Some basic Julia code
Status `~/Dropbox/class/M1399.000200/2023/M1300_000200-2023fall/lectures/02-juliaintro/Project.toml` (empty project)5×3 Matrix{Float64}:
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.05×3 Matrix{Float64}:
1.0 1.0 1.0
1.0 1.0 1.0
1.0 1.0 1.0
1.0 1.0 1.0
1.0 1.0 1.05×3 Matrix{Float64}:
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.05×3 Matrix{Float64}:
0.546293 0.12138 0.425512
0.826908 0.419831 0.227693
0.0632249 0.0312031 0.309937
0.816833 0.296741 0.656396
0.358824 0.257185 0.8631715×3 Matrix{Float16}:
0.539 0.5933 0.1494
0.2935 0.332 0.3433
0.4653 0.009766 0.4824
0.968 0.6455 0.6074
0.438 0.667 0.9535×3 Matrix{Float64}:
-0.498406 0.353918 -0.86567
-0.273643 0.0195263 0.0394816
0.392344 -1.4122 0.00153266
-0.131863 0.0317344 -0.581209
0.0795573 0.548513 -0.63726810-element Vector{Float64}:
1.0
2.0
3.0
4.0
5.0
6.0
7.0
8.0
9.0
10.0Matrices and vectors
Dimensions
5×3 Matrix{Float64}:
1.30281 1.26887 0.166915
-1.06464 0.584751 -0.303207
1.64798 0.0813088 -0.00574229
0.685489 0.448753 -0.658642
1.22546 -0.0591479 -1.21465Indexing
5×5 Matrix{Float64}:
-0.0128921 -0.404395 0.413536 1.85197 -0.516304
-0.757414 0.36058 -1.0561 0.880256 -1.78939
-1.76583 0.416184 0.577176 -0.068931 -0.903778
2.19384 -1.13248 0.865923 -0.183744 -0.039366
0.837032 -1.10723 -0.299019 -0.485402 -0.2345055-element Vector{Float64}:
-0.012892124457049585
-0.4043948586638572
0.4135355453571607
1.8519652247599696
-0.5163040102447345# getting a subset of a matrix creates a copy, but you can also create "views"
z = view(x, 1:2, 2:3)2×2 view(::Matrix{Float64}, 1:2, 2:3) with eltype Float64:
-0.404395 0.413536
0.36058 -1.05612×2 view(::Matrix{Float64}, 1:2, 2:3) with eltype Float64:
-0.404395 0.413536
0.36058 -1.05615×5 Matrix{Float64}:
-0.0128921 -0.404395 0.413536 1.85197 -0.516304
-0.757414 0.36058 0.0 0.880256 -1.78939
-1.76583 0.416184 0.577176 -0.068931 -0.903778
2.19384 -1.13248 0.865923 -0.183744 -0.039366
0.837032 -1.10723 -0.299019 -0.485402 -0.2345055×5 Matrix{Float64}:
-0.0128921 -0.404395 0.413536 1.85197 -0.516304
-0.757414 0.36058 0.0 0.880256 -1.78939
-1.76583 0.416184 0.577176 -0.068931 -0.903778
2.19384 -1.13248 0.865923 -0.183744 -0.039366
0.837032 -1.10723 -0.299019 -0.485402 -0.234505(Ptr{Float64} @0x000000010ffe2f40, Ptr{Float64} @0x000000010ffe2f40)5×5 Matrix{Float64}:
0.0 -0.404395 0.413536 1.85197 -0.516304
0.0 0.36058 0.0 0.880256 -1.78939
0.0 0.416184 0.577176 -0.068931 -0.903778
0.0 -1.13248 0.865923 -0.183744 -0.039366
0.0 -1.10723 -0.299019 -0.485402 -0.2345055×5 Matrix{Float64}:
0.0 -0.404395 0.413536 1.85197 -0.516304
0.0 0.36058 0.0 0.880256 -1.78939
0.0 0.416184 0.577176 -0.068931 -0.903778
0.0 -1.13248 0.865923 -0.183744 -0.039366
0.0 -1.10723 -0.299019 -0.485402 -0.234505Concatenate matrices
([-1.4999732352895327 1.773939277444214 0.6715225956302983; -1.3849842267185073 0.1629035112557726 0.3562080533137759; … ; -1.6065912870082713 0.30084783005095794 0.7706189876690998; 0.5121773065548649 -0.964687566685388 0.3658354011165104], [-0.4902326192447578 0.6738040576465752; 0.1070972886226452 -0.37660032519874775; … ; 0.9443998042244898 -0.1485566612569545; -0.8183848793856123 0.2236238055915957], [-1.2829660735274226 1.1957527423128549 … -0.11357622839848679 0.830600133971669; 1.7451448614828269 0.05526390872932643 … -0.7093502689866387 -0.21436808183399167; 0.30009810615719884 -1.1237165220676726 … 0.6093291761311854 -1.778493587414965])8×5 Matrix{Float64}:
-1.49997 1.77394 0.671523 -0.490233 0.673804
-1.38498 0.162904 0.356208 0.107097 -0.3766
0.391741 -1.1743 0.722154 0.55271 0.0150385
-1.60659 0.300848 0.770619 0.9444 -0.148557
0.512177 -0.964688 0.365835 -0.818385 0.223624
-1.28297 1.19575 -1.96595 -0.113576 0.8306
1.74514 0.0552639 -1.68426 -0.70935 -0.214368
0.300098 -1.12372 -0.270963 0.609329 -1.77849Dot operation
In Julia, any function f(x) can be applied elementwise to an array X with the “dot call” syntax f.(X).
5×3 Matrix{Float64}:
0.644836 0.411596 -1.22524
0.0114805 0.768921 -0.601454
0.723059 -0.914186 -2.12972
0.226376 -2.49521 0.222758
-0.435674 0.109742 -1.48675×3 Matrix{Float64}:
0.644836 0.411596 -1.22524
0.0114805 0.768921 -0.601454
0.723059 -0.914186 -2.12972
0.226376 -2.49521 0.222758
-0.435674 0.109742 -1.48675×3 Matrix{Float64}:
2.40493 5.90281 0.666123
7587.2 1.69136 2.76437
1.91273 1.19655 0.220473
19.5136 0.160615 20.1526
5.26838 83.0337 0.452433Basic linear algebra
5-element Vector{Float64}:
-0.6337948981039522
-1.235717874501824
0.43117311951580656
1.6681744799753075
0.058066487074532175×2 Matrix{Float64}:
0.380833 0.216444
-0.287348 -0.349765
-2.20059 0.091639
-0.901147 0.295597
1.15496 0.1579053×3 Matrix{Float64}:
0.963502 0.447377 0.221476
-1.90163 0.304961 1.04087
-0.158023 -1.56978 -2.065783×3 adjoint(::Matrix{Float64}) with eltype Float64:
0.963502 -1.90163 -0.158023
0.447377 0.304961 -1.56978
0.221476 1.04087 -2.06578Sparse matrices
10×10 SparseMatrixCSC{Float64, Int64} with 8 stored entries:
⋅ ⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ 0.166671 ⋅ ⋅ ⋅ ⋅ ⋅
⋅ -0.513767 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ -0.480349 ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ -1.22357 ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 2.21861 ⋅
⋅ ⋅ ⋅ ⋅ 0.728669 ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 0.802902 ⋅ # convert to dense matrix; be cautious when dealing with big data
Xfull = convert(Matrix{Float64}, X)10×10 Matrix{Float64}:
0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.166671 0.0 0.0 0.0 0.0 0.0
0.0 -0.513767 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 -0.480349 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 … 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 -1.22357 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 2.21861 0.0
0.0 0.0 0.0 0.0 0.728669 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.802902 0.010×10 SparseMatrixCSC{Float64, Int64} with 8 stored entries:
⋅ ⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ 0.166671 ⋅ ⋅ ⋅ ⋅ ⋅
⋅ -0.513767 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ -0.480349 ⋅ ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ … ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ -1.22357 ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 2.21861 ⋅
⋅ ⋅ ⋅ ⋅ 0.728669 ⋅ ⋅ ⋅ ⋅
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 0.802902 ⋅ 10-element Vector{Float64}:
0.0
0.16667062540536595
-0.5137670762120491
0.0
-0.48034908102608775
0.0
-1.2235741749446545
3.9995698640929875
0.7286685000567706
0.8029015444725927Control flow and loops
- if-elseif-else-end
forloop
- Nested
forloop:
Same as
- Exit loop:
- Exit iteration:
Functions
- Function definition
- Required arguments are separated with a comma and use the positional notation.
- Optional arguments need a default value in the signature.
- return statement is optional (value of the last expression is the return value, like R).
- Multiple outputs can be returned as a tuple, e.g.,
return out1, out2, out3.
- In Julia, all arguments to functions are passed by reference, in contrast to R and Matlab (which use pass by value).
- Implication: function arguments can be modified inside the function.
- By convention function names ending with
!indicates that function mutates at least one argument, typically the first.
- Anonymous functions, e.g.,
x -> x^2, is commonly used in collection function or list comprehensions.
- Functions can be nested:
function outerfunction()
# do some outer stuff
function innerfunction()
# do inner stuff
# can access prior outer definitions
end
# do more outer stuff
end- Functions can be vectorized using the “dot call” syntax:
Collection function
Like a series of apply functions in R.
Apply a function to each element of a collection:
Alternative “vectorization”:
5×3 Matrix{Float64}:
0.793824 0.435542 0.79834
0.00213892 0.155892 0.22172
0.0463857 0.732109 0.981782
0.973942 0.23271 0.0561392
0.709574 0.00167153 0.98742List comprehension
Type system
Every variable in Julia has a type.
Everything is a subtype of the abstract type
Any.An abstract type defines a set of types.
- Consider types in Julia that are a
Number:
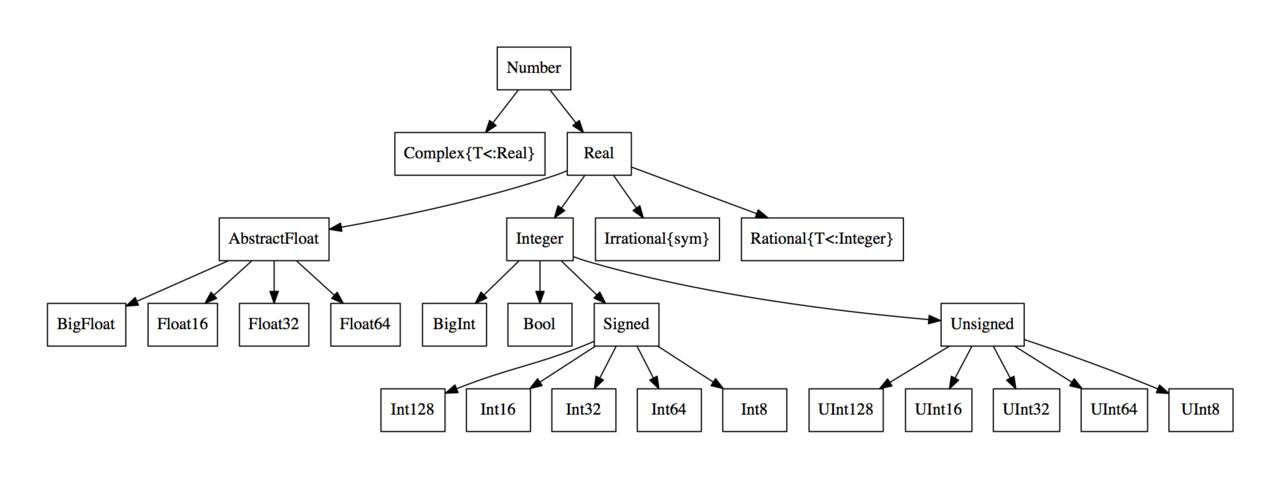
- We can explore type hierarchy with
typeof(),supertype(), andsubtypes().
5-element Vector{Float32}:
-0.8045918
0.7131479
-0.36245242
-0.5594625
-0.193414265-element Vector{Float64}:
-0.8045917749404907
0.7131478786468506
-0.3624524176120758
-0.5594624876976013
-0.19341425597667694Multiple dispatch
Multiple dispatch is a feature of some programming languages in which a function or method can be dynamically dispatched based on the run time (dynamic) type or, in the more general case, some other attribute of more than one of its arguments.
Multiple dispatch lies in the core of Julia design. It allows built-in and user-defined functions to be overloaded for different combinations of argument types.
In Juila, methods belong to functions, called generic functions.
- Let’s consider a simple “doubling” function:
- This definition is too broad, since some things, e.g., strings, cannot be added.
LoadError: MethodError: no method matching +(::String, ::String)
String concatenation is performed with [36m*[39m (See also: https://docs.julialang.org/en/v1/manual/strings/#man-concatenation).
[0mClosest candidates are:
[0m +(::Any, ::Any, [91m::Any[39m, [91m::Any...[39m)
[0m[90m @[39m [90mBase[39m [90m[4moperators.jl:578[24m[39m- This definition is correct but too restrictive, since any
Numbercan be added.
This definition will automatically work on the entire type tree above!
A lot nicer than
methods(func) displays all methods defined for func.
# 3 methods for generic function g from [35mMain[39m:
- g(x::Float64) in Main at In[101]:1
- g(x::Number) in Main at In[102]:1
- g(x) in Main at In[98]:1
When calling a function with multiple definitions, Julia will search from the narrowest signature to the broadest signature.
@which func(x)marco tells which method is being used for argument signaturex.
- R also makes use of generic functions and multiple dispatch (see http://adv-r.had.co.nz/OO-essentials.html#s3), but it is not fully optimized.
JIT
- Julia’s efficiency results from its capability to infer the types of all variables within a function and then call LLVM (compiler) to generate optimized machine code at run-time.
Consider the g (doubling) function defined earlier. This function will work on any type which has a method for +.
Step 1: Parse Julia code into AST.
Step 2: Type inference according to input type.
MethodInstance for g(::Int64)
from g(x::Number) @ Main In[102]:1
Arguments
#self#::Core.Const(g)
x::Int64
Body::Int64
1 ─ %1 = (x + x)::Int64
└── return %1
Step 3: Compile into LLVM bytecode
; @ In[102]:1 within `g`
define i64 @julia_g_5071(i64 signext %0) #0 {
top:
; ┌ @ int.jl:87 within `+`
%1 = shl i64 %0, 1
; └
ret i64 %1
}We didn’t provide a type annotation. But different LLVM code gets generated depending on the argument type!
In R or Python,
g(2)andg(2.0)would use the same code for both.In Julia,
g(2)andg(2.0)dispatch to optimized code forInt64andFloat64, respectively.
For integer input x, LLVM compiler is smart enough to know x + x is simple shifting x by 1 bit, which is faster than addition.
- Step 4: Lowest level is the assembly code, which is machine dependent.
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 13, 0
.globl _julia_g_5110 ## -- Begin function julia_g_5110
.p2align 4, 0x90
_julia_g_5110: ## @julia_g_5110
; ┌ @ In[102]:1 within `g`
.cfi_startproc
## %bb.0: ## %top
; │┌ @ int.jl:87 within `+`
leaq (%rdi,%rdi), %rax
; │└
retq
.cfi_endproc
; └
## -- End function
.subsections_via_symbols1st instruction adds the content of the general purpose 64-bit register (a small memory inside the CPU) RDI to itself, and load the result into another register RAX. The addition here is the integer arithmetic.
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 13, 0
.globl _julia_g_5114 ## -- Begin function julia_g_5114
.p2align 4, 0x90
_julia_g_5114: ## @julia_g_5114
; ┌ @ In[101]:1 within `g`
.cfi_startproc
## %bb.0: ## %top
; │┌ @ float.jl:408 within `+`
vaddsd %xmm0, %xmm0, %xmm0
; │└
retq
.cfi_endproc
; └
## -- End function
.subsections_via_symbols