Julia Version 1.9.3
Commit bed2cd540a1 (2023-08-24 14:43 UTC)
Build Info:
Official https://julialang.org/ release
Platform Info:
OS: macOS (x86_64-apple-darwin22.4.0)
CPU: 8 × Intel(R) Core(TM) i5-8279U CPU @ 2.40GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.6 (ORCJIT, skylake)
Threads: 2 on 8 virtual coresEigen- and Singular Value Decompositions
Advanced Statistical Computing
Joong-Ho Won
Seoul National University
October 2023
Status `~/Dropbox/class/M1399.000200/2023/M1300_000200-2023fall/lectures/13-eigsvd/Project.toml`
[7d9fca2a] Arpack v0.5.4
[6e4b80f9] BenchmarkTools v1.3.2
[b51810bb] MatrixDepot v1.0.11
[b8865327] UnicodePlots v3.6.0
[2f01184e] SparseArraysIntroduction
We already saw wide applications of QR decomposition in least squares problem and solving square and underdetermined system of linear equations.
EVD and SVD can be deemed as more thorough orthogonalization of a matrix.
Review: Eigenvalue Decomposition
- Eigenvalue decomposition (EVD): \(\mathbf{A} = \mathbf{X} \Lambda \mathbf{X}^{-1}\).
- \(\Lambda = \text{diag}(\lambda_1,\ldots,\lambda_n)\) collects the eigenvalues of \(\mathbf{A}\).
- Columns of \(\mathbf{X}\) are the eigenvectors.
- Not all matrices have EVD: \[ \mathbf{A} = \begin{bmatrix} 2 & 1 & 0 \\ 0 & 2 & 1 \\ 0 & 0 & 2 \end{bmatrix} \] has only a single independent eigenvector \(\mathbf{e}_1 = (1, 0, 0)^T\) associated with the multiple eigenvalue 2.
In most statistical applications, we deal with eigenvalues/eigenvectors of symmetric matrices. The eigenvalues and eigenvectors of a real symmetric matrix are real.
Eigenvalue decompostion of a symmetric matrix: \(\mathbf{A} = \mathbf{U} \Lambda \mathbf{U}^T\), where
- \(\Lambda = \text{diag}(\lambda_1,\ldots,\lambda_n)\)
- columns of \(\mathbf{U}\) are the eigenvectors, which are (or can be chosen to be) mutually orthonormal. Thus \(\mathbf{U}\) is an orthogonal matrix.
A real symmetric matrix is positive semidefinite (positive definite) if and only if all eigenvalues are nonnegative (positive).
Schur decomposition: every square matrix \(\mathbf{A}\) can be decomposed \(\mathbf{A} = \mathbf{Q}\mathbf{T}\mathbf{Q}^*\)
- \(\mathbf{T}\) is upper triangular, with eigenvalues on the diagonal.
- \(\mathbf{Q}\) is unitary: \(\mathbf{Q}^*\mathbf{Q} = \mathbf{I}\).
- Columns of \(\mathbf{Q}\) form a sequence of nested invariant spaces with respect to \(\mathbf{A}\): let \(\mathbf{Q} = [\mathbf{q}_1 | \dotsb | \mathbf{q}_n ]\). Then \(\text{span}(\mathbf{q}_1, \dotsc, \mathbf{q}_k) = \text{span}(\mathbf{A}\mathbf{q}_1, \dotsc, \mathbf{A}\mathbf{q}_k)\).
Spectral radius \(\rho(\mathbf{A}) = \max_i |\lambda_i|\).
If \(\mathbf{A} \in \mathbb{R}^{n \times n}\) a square matrix (not necessarily symmetric), then \(\text{tr}(\mathbf{A}) = \sum_i \lambda_i\) and \(\det(\mathbf{A}) = \prod_i \lambda_i\).
Review: Singular Value Decomposition
- For a rectangular matrix \(\mathbf{A} \in \mathbb{R}^{m \times n}\), let \(p = \min\{m,n\}\), then we have the SVD \[
\mathbf{A} = \mathbf{U} \Sigma \mathbf{V}^T,
\] where
- \(\mathbf{U} = (\mathbf{u}_1,\ldots,\mathbf{u}_m) \in \mathbb{R}^{m \times m}\) is orthogonal, i.e. \(\mathbf{U}^T\mathbf{U} = \mathbf{U}\mathbf{U}^T = \mathbf{I}_m\).
- \(\mathbf{V} = (\mathbf{v}_1,\ldots,\mathbf{v}_n) \in \mathbb{R}^{n \times n}\) is orthogonal, i.e. \(\mathbf{V}^T\mathbf{V} = \mathbf{V}\mathbf{V}^T = \mathbf{I}_n\).
- \(\Sigma = [\text{diag}(\sigma_1, \ldots, \sigma_p)~\mathbf{0}]~\text{or}~[\text{diag}(\sigma_1, \ldots, \sigma_p); \mathbf{0}] \in \mathbb{R}^{m \times n}\), \(\sigma_1 \ge \sigma_2 \ge \cdots \ge \sigma_p \ge 0\).
\(\sigma_i\) are called the singular values, \(\mathbf{u}_i\) are the left singular vectors, and \(\mathbf{v}_i\) are the right singular vectors.
- Thin/skinny SVD. Assume \(m \ge n\). \(\mathbf{A}\) can be factored as \[
\mathbf{A} = \mathbf{U}_n \Sigma_n \mathbf{V}^T = \sum_{i=1}^n \sigma_i \mathbf{u}_i \mathbf{v}_i^T,
\] where
- \(\mathbf{U}_n \in \mathbb{R}^{m \times n}\), \(\mathbf{U}_n^T \mathbf{U}_n = \mathbf{I}_n\)
- \(\mathbf{V} \in \mathbb{R}^{n \times n}\), \(\mathbf{V}^T \mathbf{V} = \mathbf{V} \mathbf{V}^T \mathbf{I}_n\)
- \(\Sigma_n = \text{diag}(\sigma_1,\ldots,\sigma_n) \in \mathbb{R}^{n \times n}\), \(\sigma_1 \ge \sigma_2 \ge \cdots \ge \sigma_n \ge 0\)
- Denote \(\sigma(\mathbf{A})=(\sigma_1,\ldots,\sigma_p)^T\). Then
- \(r = \text{rank}(\mathbf{A}) = \# \text{ nonzero singular values} = \|\sigma(\mathbf{A})\|_0\)
- \(\mathbf{A} = \mathbf{U}_r \Sigma_r \mathbf{V}_r^T = \sum_{i=1}^r \sigma_i \mathbf{u}_i \mathbf{v}_i^T\)
- \(\|\mathbf{A}\|_{\text{F}} = (\sum_{i=1}^p \sigma_i^2)^{1/2} = \|\sigma(\mathbf{A})\|_2\)
- \(\|\mathbf{A}\|_2 = \sigma_1 = \|\sigma(\mathbf{A})\|_\infty\)
- \(r = \text{rank}(\mathbf{A}) = \# \text{ nonzero singular values} = \|\sigma(\mathbf{A})\|_0\)
Relation between EVD and SVD
- Using thin SVD, \(\mathbf{A}^T \mathbf{A} = \mathbf{V} \Sigma^2 \mathbf{V}^T\) and \(\mathbf{A} \mathbf{A}^T = \mathbf{U} \Sigma^2 \mathbf{U}^T\).
- In principle we can obtain SVD of \(\mathbf{A}\) by doing two EVDs.
- In fact, using thin SVD, \[ \small \begin{bmatrix} \mathbf{0}_{n \times n} & \mathbf{A}^T \\ \mathbf{A} & \mathbf{0}_{m \times m} \end{bmatrix} = \frac{1}{\sqrt 2} \begin{bmatrix} \mathbf{V} & \mathbf{V} \\ \mathbf{U} & -\mathbf{U} \end{bmatrix} \begin{bmatrix} \Sigma & \mathbf{0}_{n \times n} \\ \mathbf{0}_{n \times n} & - \Sigma \end{bmatrix} \frac{1}{\sqrt 2} \begin{bmatrix} \mathbf{V}^T & \mathbf{U}^T \\ \mathbf{V}^T & - \mathbf{U}^T \end{bmatrix}. \] Hence any symmetric EVD solver can produce the SVD of a matrix \(\mathbf{A}\) without forming \(\mathbf{A} \mathbf{A}^T\) or \(\mathbf{A}^T \mathbf{A}\).
Applications of EVD and SVD
1. Principal Components Analysis
\(\mathbf{X} \in \mathbb{R}^{n \times p}\) is a centered data matrix.
Perform SVD \(\mathbf{X} = \mathbf{U} \Sigma \mathbf{V}^T\) or equivalently eigendecomposition \(\mathbf{X}^T \mathbf{X} = \mathbf{V} \Sigma^2 \mathbf{V}^T\). The linear combinations \(\tilde{\mathbf{x}}_i = \mathbf{X} \mathbf{v}_i\) are the principal components (PC) and have variance \(\sigma_i^2\).
Dimension reduction: reduce dimensionality \(p\) to \(q \ll p\). Use top PCs \(\tilde{\mathbf{x}}_1, \ldots, \tilde{\mathbf{x}}_q\) in visualization and downstream analysis.
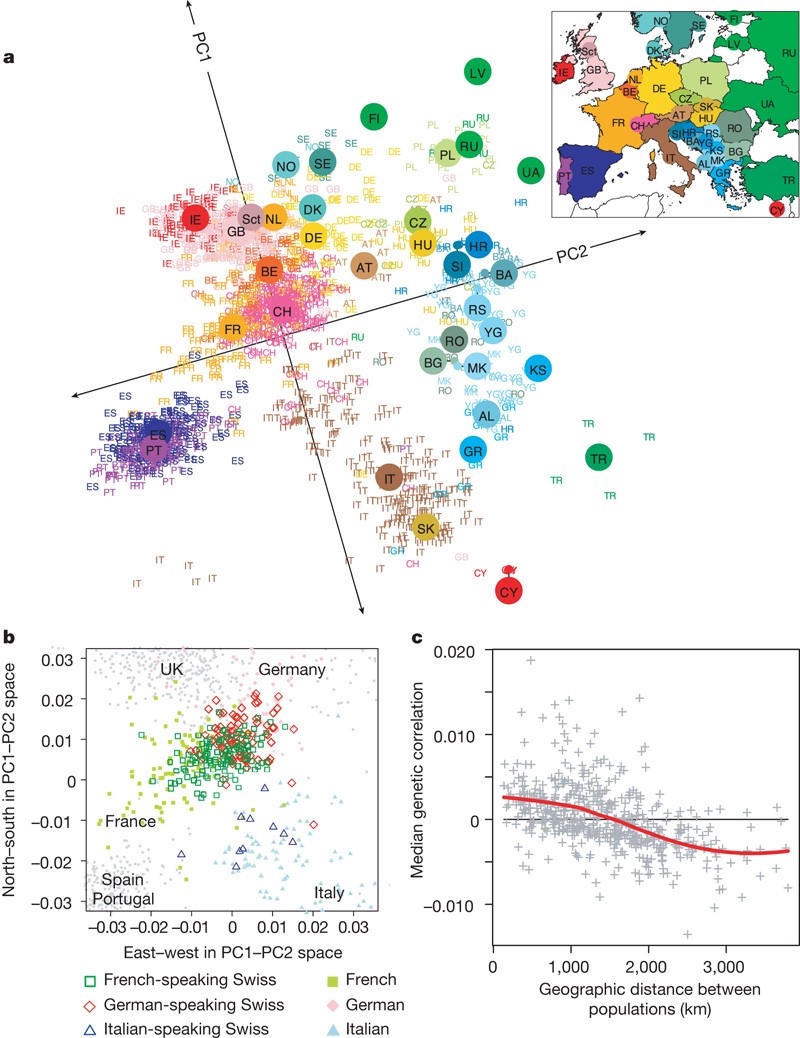
Genes mirror geography within Europe by Novembre et al., Nature 456, 98–101 (2008)
- Use PCs to adjust for confounding — a serious issue in association studies with large data sets.
- Use of PCA to adjust for confounding in modern genetic studies is proposed in the paper Principal components analysis corrects for stratification in genome-wide association studies by Price, A., Patterson, N., Plenge, R. et al., Nature Genetics 38, 904–909 (2006). It has been cited 6970 times as of Oct 30, 2023.
2. Low rank approximation
- Goal: Find a low rank approximation of data matrix \(\mathbf{X}\) in, e.g., image/data compression.
Eckart-Young theorem: \[ \min_{\text{rank}(\mathbf{Y})=r} \|\mathbf{X} - \mathbf{Y} \|_{\text{F}}^2 \] is achieved by \(\mathbf{Y} = \sum_{i=1}^r \sigma_i \mathbf{u}_i \mathbf{v}_i^T\) with optimal value \(\sum_{i=r}^{p} \sigma_i^2\), where \((\sigma_i, \mathbf{u}_i, \mathbf{v}_i)\) are singular values and vectors of \(\mathbf{X}\).
- Gene Golub’s \(897 \times 598\) picture requires \(3 \times 897 \times 598 \times 8 = 12,873,744\) bytes (3 RGB channels).

- Rank 50 approximation requires \(3 \times 50 \times (897 + 598) \times 8 = 1,794,000\) bytes.

- Rank 12 approximation requires \(12 \times (2691+598) \times 8 = 430,560\) bytes.

Source: Professor SVD
3. Moore-Penrose (MP) pseudoinverse
- MP pseudoinverse of a rectangular matrix \(\mathbf{A}\) is defined as a matrix \(\mathbf{A}^{\dagger}\) such that
- \(\mathbf{A}\mathbf{A}^{\dagger}\mathbf{A} = \mathbf{A}\);
- \(\mathbf{A}^{\dagger}\mathbf{A}\mathbf{A}^{\dagger} = \mathbf{A}^{\dagger}\);
- \((\mathbf{A}\mathbf{A}^{\dagger})^T = \mathbf{A}\mathbf{A}^{\dagger}\);
- \((\mathbf{A}^{\dagger}\mathbf{A})^T = \mathbf{A}^{\dagger}\mathbf{A}\).
- Using thin SVD, \[
\mathbf{A}^{\dagger} = \mathbf{V} \Sigma^{\dagger} \mathbf{U}^T,
\] where \(\Sigma^{\dagger} = \text{diag}(\sigma_1^{-1}, \ldots, \sigma_r^{-1}, 0, \ldots, 0)\), \(r= \text{rank}(\mathbf{A})\). This is how the
pinvfunction is implemented in Julia.
3×5 Matrix{Float64}:
-0.0968407 -0.340739 0.479724 -0.217847 0.183095
-0.330339 -0.0637448 -0.455237 -0.23351 0.222205
0.190843 0.187126 0.378086 0.507667 0.178208
pinv(A::AbstractMatrix{T}; atol, rtol) where T in LinearAlgebra at /Applications/Julia-1.9.app/Contents/Resources/julia/share/julia/stdlib/v1.9/LinearAlgebra/src/dense.jl:1469
4. Least squares via SVD
When \(\mathbf{X}\) does not have full column rank, the Moore-Penrose pseudoinverse gives the minimum \(\ell_2\) norm solution to OLS (recall Lecture Notes on Linear Regression).
To see this, let \(\mathbf{X} = \sum_{i=1}^{\min(n,p)}\sigma_i\mathbf{u}_i\mathbf{v}_i^T\) (full SVD) , \(r=\text{rank}(\mathbf{X})\) and \(\mathbf{\beta} = \sum_{j=1}^p \alpha_j\mathbf{v}_j\).
\[ \small \begin{split} \|\mathbf{y} - \mathbf{X}\beta\|_2^2 &= \|\mathbf{y} - \mathbf{U}\Sigma_p\mathbf{V}^T\beta\|_2^2 \\ &= \|\sum_{i=1}^n(\mathbf{u}_i^T\mathbf{y})\mathbf{u}_i - \sum_{i=1}^{\min(n,p)}\sigma_i\alpha_i\mathbf{u}_i\|_2^2 = \|\sum_{i=1}^n(\mathbf{u}_i^T\mathbf{y} - \sigma_i\alpha_i)\mathbf{u}_i\|_2^2 = \sum_{i=1}^n(\mathbf{u}_i^T\mathbf{y} - \sigma_i\alpha_i)^2 \\ &= \sum_{i=1}^r(\mathbf{u}_i^T\mathbf{y} - \sigma_i\alpha_i)^2 + \sum_{i=r+1}^n(\mathbf{u}_i^T\mathbf{y})^2 \end{split} \]
Thus \(\hat{\alpha}_j = \frac{1}{\sigma_j}\mathbf{u}_j^T\mathbf{y}\) for \(j=1,\dotsc, r\) but is arbitrary for \(j>r\). The minimum \(\ell_2\) norm solution is given by setting \(\hat{\alpha}_j=0\) for \(j>r\), resulting in
\[ \small \hat\beta = \sum_{j=1}^r\frac{\mathbf{u}_j^T\mathbf{y}}{\sigma_j}\mathbf{v}_j = \mathbf{X}^{\dagger}\mathbf{y} \]
and \[ \small \begin{eqnarray*} \widehat{\mathbf{y}} &=& \mathbf{X} \widehat \beta = \mathbf{U}_r \mathbf{U}_r^T \mathbf{y}. \end{eqnarray*} \]
In general, SVD is more expensive than other approaches (Cholesky, QR). In some applications, SVD is computed for other purposes. Then, we get least squares solution for free.
5. Ridge regression
In ridge regression, we minimize \[ \small \|\mathbf{y} - \mathbf{X} \beta\|_2^2 + \lambda \|\beta\|_2^2, \] where \(\lambda\) is a tuning parameter.
Ridge regression by augmented linear regression: Ridge regression problem is equivalent to \[ \small \left\| \begin{pmatrix} \mathbf{y} \\ \mathbf{0}_p \end{pmatrix} - \begin{pmatrix} \mathbf{X} \\ \sqrt \lambda \mathbf{I}_p \end{pmatrix} \beta \right\|_2^2. \] Therefore any methods for linear regression (e.g., LSQR) can be applied.
Ridge regression by method of normal equation: The normal equation for the ridge problem is \[ \small (\mathbf{X}^T \mathbf{X} + \lambda \mathbf{I}_p) \beta = \mathbf{X}^T \mathbf{y}. \] Therefore Cholesky decomposition can be used.
Ridge regression by SVD: If we obtain the (thin) SVD of \(\mathbf{X}\) \[ \small \mathbf{X} = \mathbf{U} \Sigma_{p} \mathbf{V}^T, \] then the normal equation reads \[ \small \mathbf{V}^T(\Sigma^2 + \lambda \mathbf{I}_p) \mathbf{V}^T \beta = \mathbf{V}^T\Sigma \mathbf{U}^T \mathbf{y}. \]
We get \[ \small \widehat \beta (\lambda) = \mathbf{V} (\Sigma^2 + \lambda \mathbf{I}_p)^{-1}\Sigma \mathbf{U}^T \mathbf{y} = \sum_{i=1}^p \frac{\sigma_i \mathbf{u}_i^T \mathbf{y}}{\sigma_i^2 + \lambda} \mathbf{v}_i = \sum_{i=1}^r \frac{\sigma_i \mathbf{u}_i^T \mathbf{y}}{\sigma_i^2 + \lambda} \mathbf{v}_i, \quad r = \text{rank}(\mathbf{X}). \]
It is clear that \[ \small \begin{eqnarray*} \lim_{\lambda \to 0} \widehat \beta (\lambda) = \mathbf{X}^{\dagger}\mathbf{y}, \end{eqnarray*} \] the minimum \(\ell_2\) norm solution, and \(\|\widehat \beta (\lambda)\|_2\) is monotone decreasing as \(\lambda\) increases.
Only one SVD is needed for all \(\lambda\), in contrast to the method of augmented linear regression or Cholesky.
Algorithms for EVD
Any EVD solver must be iterative.
Abel (1824) showed that the real root of a polynomial of degree 5 or more with rational coefficients cannot be written using any expression involving rational numbers, addtion, subtraction, multiplication, division, and \(k\)th roots.
This means that no algorithm can produce the exact roots of the characteristic polynomial of a matrix, i.e., eigenvalues, in a finite number of steps.
“Direct” EVD solver refers to a solver that reduces to a general matrix to a special form in finite flops, and then apply iterative methods that converges to EVD.
For ease of exposition, we restrict attention to real symmetric matrices, i.e., we assume \(\mathbf{A}=\mathbf{A}^T \in \mathbb{R}^{n \times n}\).
One eigen-pair: power iteration
Iterates according to \[ \small \begin{eqnarray*} \mathbf{x}^{(t)} &\gets& \frac{1}{\|\mathbf{A} \mathbf{x}^{(t-1)}\|} \mathbf{A} \mathbf{x}^{(t-1)} \end{eqnarray*} \] from an initial guess \(\mathbf{x}^{(0)}\) of unit norm.
Obviously, \(\mathbf{x}^{(t)} \propto \mathbf{A}^t \mathbf{x}^{(0)}\), hence the name. (We normalize so that \(\Vert \mathbf{x}^{(t)} \Vert = 1\)).
Suppose we arrange eigenvalues \(|\lambda_1| > |\lambda_2| \ge \cdots \ge |\lambda_n|\) (the first inequality strict) with corresponding eigenvectors \(\mathbf{u}_i\), and expand \(\mathbf{x}^{(0)} = c_1 \mathbf{u}_1 + \cdots + c_n \mathbf{u}_n\), then \[ \small \begin{eqnarray*} \mathbf{x}^{(t)} &=& \frac{\left( \sum_i \lambda_i^t \mathbf{u}_i \mathbf{u}_i^T \right) \left( \sum_i c_i \mathbf{u}_i \right)}{\|\left( \sum_i \lambda_i^t \mathbf{u}_i \mathbf{u}_i^T \right) \left( \sum_i c_i \mathbf{u}_i \right)\|} \\ &=& \frac{\sum_i c_i \lambda_i^t \mathbf{u}_i}{\|\sum_i c_i \lambda_i^t \mathbf{u}_i\|} \\ &=& \frac{c_1 \mathbf{u}_1 + c_2 (\lambda_2/\lambda_1)^t \mathbf{u}_2 + \cdots + c_n (\lambda_n/\lambda_1)^t \mathbf{u}_n}{\|c_1 \mathbf{u}_1 + c_2 (\lambda_2/\lambda_1)^t \mathbf{u}_2 + \cdots + c_n (\lambda_n/\lambda_1)^t \mathbf{u}_n\|} \left( \frac{\lambda_1}{|\lambda_1|} \right)^t. \end{eqnarray*} \] Thus \(\mathbf{x}^{(t)}/\left( \frac{\lambda_1}{|\lambda_1|} \right)^t \to \frac{c_1}{|c_1|}\mathbf{u}_1\) as \(t \to \infty\). The convergence rate is \(|\lambda_2|/|\lambda_1|\) (linear/geometric convergence).
\(\lambda_1^{(t)} = \mathbf{x}^{(t)T} \mathbf{A} \mathbf{x}^{(t)}\) converges to \(\lambda_1\).
using Random, LinearAlgebra
Random.seed!(280)
n = 5
A = Symmetric(randn(n, n), :U)
Aeig = eigen(A) # we basically want to know how this function worksEigen{Float64, Float64, Matrix{Float64}, Vector{Float64}}
values:
5-element Vector{Float64}:
-3.5582775705641994
-1.424888979702748
0.4093807500562252
1.8475495594338596
3.0216689122421685
vectors:
5×5 Matrix{Float64}:
0.591789 0.420034 0.116011 -0.492886 -0.465792
0.474641 -0.502806 -0.247432 -0.420409 0.532856
-0.573199 -0.228009 -0.320981 -0.628095 -0.349173
0.186207 0.173967 -0.897576 0.318546 -0.167173
-0.247532 0.698931 -0.129021 -0.29042 0.59096Variants of power iteration
Inverse iteration: Apply power iteration to \(\mathbf{A}^{-1}\) to find the eigen-pair of smallest absolute value. (May pre-compute LU or Cholesky of \(\mathbf{A}\)).
Shifted inverse iteration: Apply power iteration to \((\mathbf{A}-\mu\mathbf{I})^{-1}\) to find the eigen-pair of closed to \(\mu\).
- Converges linearly to an eigenvalue close to the pre-specified \(\mu\).
Rayleigh quotient iteration: Substitute the shift \(\mu\) in shifted inverse iteration with Rayleigh quotient \(\mathbf{v}^{(t) T}\mathbf{A}\mathbf{v}^{(t)}/\mathbf{v}^{(t) T}\mathbf{v}^{(t)}\).
- Converges cubically to the eigen-pair closest to \(\mathbf{v}^{(0)}\).
Example: PageRank problem seeks top left eigenvector of transition matrix \(\mathbf{P}\) and costs \(O(n)\) per iteration.
Top \(r\) eigen-pairs: orthogonal iteration
= simultaneous iteration, block power iteration
Motivation
- Rewrite the power method: \[ \begin{eqnarray*} \mathbf{z}^{(t)} &\gets& \mathbf{A} \mathbf{x}^{(t-1)} \\ (\mathbf{x}^{(t)}, \Vert \mathbf{z}^{(t)}\Vert) &\gets& \texttt{qr}(\mathbf{z}^{(t)}) \quad (\|\mathbf{z}^{(t)}\|\mathbf{x}^{(t)} = \mathbf{z}^{(t)}) \end{eqnarray*} \] The second step is the first iteration of the Gram-Schmidt QR.
Algorithm
- Initialize \(\tilde{\mathbf{Q}}^{(0)} \in \mathbb{R}^{n \times r}\) with orthonormal columns
- For \(t=1,2,\ldots\),
- \(\mathbf{Z}^{(t)} \gets \mathbf{A} \tilde{\mathbf{Q}}^{(t-1)}\)
- \((\tilde{\mathbf{Q}}^{(t)}, \tilde{\mathbf{R}}^{(t)}) \gets \texttt{qr}(\mathbf{Z}^{(t)})\) (reduced QR)
- \(\mathbf{Z}^{(t)} \gets \mathbf{A} \tilde{\mathbf{Q}}^{(t-1)}\)
Orthogonal iteration is a generalization of the power method to a higher dimensional invariant subspace.
It can be shown \(\tilde{\mathbf{Q}}^{(t)}\) converges to the eigenspace of the largest \(r\) eigenvalues if they are real and separated from remaining spectrum. The convergence rate is \(\max_{k=1,\dotsc,r}|\lambda_{k+1}|/|\lambda_k|\).
To see that orthogonal iteration is a generalization of the power method, observe that \[ \small \begin{aligned} \mathbf{A}\tilde{\mathbf{Q}}^{(0)} &= \mathbf{Z}^{(1)} = \tilde{\mathbf{Q}}^{(1)}\hat{\mathbf{R}}^{(1)}, \quad \hat{\mathbf{R}}^{(1)} = \tilde{\mathbf{R}}^{(1)} \\ \mathbf{A}^2\tilde{\mathbf{Q}}^{(0)} &= (\mathbf{A}\tilde{\mathbf{Q}}^{(1)})\hat{\mathbf{R}}^{(1)} \\ &= \mathbf{Z}^{(2)}\hat{\mathbf{R}}^{(1)} = \tilde{\mathbf{Q}}^{(2)}\tilde{\mathbf{R}}^{(2)}\hat{\mathbf{R}}^{(1)} = \tilde{\mathbf{Q}}^{(2)}\hat{\mathbf{R}}^{(2)} \\ \mathbf{A}^3\tilde{\mathbf{Q}}^{(0)} &= (\mathbf{A}\tilde{\mathbf{Q}}^{(2)})\hat{\mathbf{R}}^{(2)} \\ &= \mathbf{Z}^{(3)}\hat{\mathbf{R}}^{(2)} = \tilde{\mathbf{Q}}^{(3)}\tilde{\mathbf{R}}^{(3)}\hat{\mathbf{R}}^{(2)} = \tilde{\mathbf{Q}}^{(3)}\hat{\mathbf{R}}^{(3)} \\ & \vdots \end{aligned} \] So, \[ \small \mathbf{A}^t\tilde{\mathbf{Q}}^{(0)} = \mathbf{Z}^{(t)}\hat{\mathbf{R}}^{(t-1)} = \tilde{\mathbf{Q}}^{(t)}\hat{\mathbf{R}}^{(t)}, \quad \hat{\mathbf{R}}^{(t)} = \tilde{\mathbf{R}}^{(t)} \tilde{\mathbf{R}}^{(t-1)} \dotsb \tilde{\mathbf{R}}^{(1)} . \]
Since \(\hat{\mathbf{R}}^{(t)}\) is upper triangular (why?), \(\tilde{\mathbf{Q}}^{(t)}\hat{\mathbf{R}}^{(t)}\) is the reduced QR decomposition of \(\mathbf{A}^t\tilde{\mathbf{Q}}^{(0)}\), and \(\tilde{\mathbf{Q}}^{(t)}\) is orthonormal basis of \(\text{col}(\mathbf{A}^t\tilde{\mathbf{Q}}^{(0)})\).
Full EVD (\(r=n\)): QR iteration
Algorithm
- \(\mathbf{A}^{(0)} \gets \mathbf{A}\)
- For \(t=1,2,\ldots\),
- \((\mathbf{Q}^{(t)}, \mathbf{R}^{(t)}) \gets \texttt{qr}(\mathbf{A}^{(t-1)})\) (full QR)
- \(\mathbf{A}^{(t)} \gets \mathbf{R}^{(t)}\mathbf{Q}^{(t)}\)
Explanation
It can be shown that QR iteration is equivalent to the orthogonal iteration on \(\mathbf{A}\) starting with \(\mathbf{Q}^{(0)}=\mathbf{I}_n\). Specifically, \[ \small \begin{split} \tilde{\mathbf{R}}^{(t)} &= \mathbf{R}^{(t)} \\ \tilde{\mathbf{Q}}^{(t)} &= \mathbf{Q}^{(1)} \mathbf{Q}^{(2)} \dotsb \mathbf{Q}^{(t)} \\ \mathbf{A}^{(t)} &= (\tilde{\mathbf{Q}}^{(t)})^T\mathbf{A}\tilde{\mathbf{Q}}^{(t)} . \end{split} \]
Also note that \[ \small \mathbf{A}^t = \tilde{\mathbf{Q}}^{(t)}\hat{\mathbf{R}}^{(t)} . \]
Take \(r=n\) in the orthogonal iteration. Then \(\tilde{\mathbf{Q}}^{(t)}\) converges to \(\mathbf{U}\) up to sign changes. This implies that \[ \small \mathbf{A}^{(t)} = (\tilde{\mathbf{Q}}^{(t)})^T \mathbf{A} \tilde{\mathbf{Q}}^{(t)} \] converges to a diagonal form \(\boldsymbol{\Lambda} = \text{diag}(\lambda_1, \ldots, \lambda_n)\).
Linear convergence rate.
QR iteration with shifts
Algorithm
- \(\mathbf{A}^{(0)} \gets \mathbf{A}\)
- For \(t=1,2,\ldots\),
- Pick a shift \(\mu_t\) (e.g., \(\mu_t = \mathbf{A}_{nn}^{(t)}\))
- \((\mathbf{Q}^{(t)}, \mathbf{R}^{(t)}) \gets \texttt{qr}(\mathbf{A}^{(t-1)} - \mu_t\mathbf{I})\)
- \(\mathbf{A}^{(t)} \gets \mathbf{R}^{(t)}\mathbf{Q}^{(t)} + \mu_t\mathbf{I}\)
Can be shown to be equivalent to simultaneous shifted inverse iteration starting with \[ \mathbf{Q}^{(0)} = \mathbf{P} = \begin{bmatrix} & & & 1 \\ & & 1 & \\ & \dotsc & & \\ 1 & & & \end{bmatrix} \]
\(\mu_t = \mathbf{A}_{nn}^{(t)}\) is a good choice for the shift (and free to compute!), with cubic convergence (cf. Rayleigh quotient shift).
Practical QR iteration
Implemented in LAPACK: used by Julia, Matlab, R.
General QR iteration is expensive: \(O(n^3)\) per iteration.
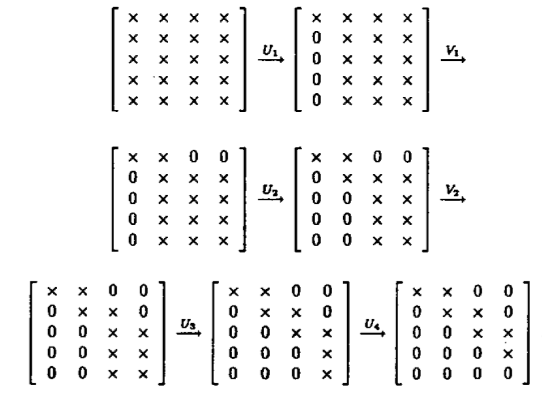
Tridiagonalization (by Householder) + implicit shifted QR iteration on the tridiagonal matrix.
- Direct phase: Householder tridiagonalization: \(4n^3/3\) for eigenvalues only, \(8n^3/3\) for both eigenvalues and eigenvectors. (Why can’t we apply Householder to make it diagonal directly?)
\[ \small \mathbf{Q}_1^T\mathbf{A} = \begin{bmatrix} \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \end{bmatrix} % \rightarrow % \mathbf{Q}_1^T\mathbf{A}\mathbf{Q}_1 = \begin{bmatrix} \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \end{bmatrix} \] vs. \[ \small \mathbf{Q}_1^T\mathbf{A} = \begin{bmatrix} \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \end{bmatrix} % \rightarrow % \mathbf{Q}_1^T\mathbf{A}\mathbf{Q}_1 = \begin{bmatrix} \boldsymbol{\times} & \boldsymbol{\times} & 0 & 0 & 0 \\ \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \\ 0 & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} & \boldsymbol{\times} \end{bmatrix} \]
- Iterative phase: Built on QR iteration with shifts. Tridiangonal structure allows the QR decomposition cheap (“implicit Q theorem”). On average 1.3-1.6 QR iteration per eigenvalue, \(\sim 20n\) flops per iteration. So total operation count is about \(30n^2\). Eigenvectors need an extra of about \(6n^3\) flops.
| Phase | Eigenvalue | Eigenvector |
|---|---|---|
| Tridiagonal reduction | \(4n^3/3\) | + \(4n^3/3\) |
| implicit shifted QR | \(\sim 30n^2\) | + \(\sim 6n^3\) |
- Take-home message: Don’t request eigenvectors unless necessary. Use
eigvalsin Julia to request only eigenvalues.
Unsymmetric EVD
Reduction to the upper Hessenberg form (upper triangular + subdiagonal)
The unsymmetric QR algorithm obtains the real Schur decomposition of the Hessenberg matrix.
- Implicit Q theorem still applies, but more expensive.
Example
Julia functions: eigen, eigen!, eigvals, eigvecs, eigmax, eigmin.
Eigen{Float64, Float64, Matrix{Float64}, Vector{Float64}}
values:
5-element Vector{Float64}:
-3.5582775705641994
-1.424888979702748
0.4093807500562252
1.8475495594338596
3.0216689122421685
vectors:
5×5 Matrix{Float64}:
0.591789 0.420034 0.116011 -0.492886 -0.465792
0.474641 -0.502806 -0.247432 -0.420409 0.532856
-0.573199 -0.228009 -0.320981 -0.628095 -0.349173
0.186207 0.173967 -0.897576 0.318546 -0.167173
-0.247532 0.698931 -0.129021 -0.29042 0.590965-element Vector{Float64}:
-3.5582775705641994
-1.424888979702748
0.4093807500562252
1.8475495594338596
3.02166891224216855×5 Matrix{Float64}:
0.591789 0.420034 0.116011 -0.492886 -0.465792
0.474641 -0.502806 -0.247432 -0.420409 0.532856
-0.573199 -0.228009 -0.320981 -0.628095 -0.349173
0.186207 0.173967 -0.897576 0.318546 -0.167173
-0.247532 0.698931 -0.129021 -0.29042 0.590965×5 Matrix{Float64}:
0.0139273 0.0291782 0.292971 -0.39582 -0.215047
0.0291782 0.09844 0.271352 0.477086 0.527932
0.292971 0.271352 0.376726 0.672617 0.203571
-0.39582 0.477086 0.672617 2.00114 0.127733
-0.215047 0.527932 0.203571 0.127733 -0.158166
inv(A::Eigen) in LinearAlgebra at /Applications/Julia-1.9.app/Contents/Resources/julia/share/julia/stdlib/v1.9/LinearAlgebra/src/eigen.jl:436
det(A::Eigen) in LinearAlgebra at /Applications/Julia-1.9.app/Contents/Resources/julia/share/julia/stdlib/v1.9/LinearAlgebra/src/eigen.jl:437
5-element Vector{Float64}:
-3.5582775705642056
-1.4248889797027493
0.40938075005622393
1.847549559433859
3.021668912242168Don’t request eigenvectors unless needed.
using BenchmarkTools, Random, LinearAlgebra
Random.seed!(280)
n = 1000
A = Symmetric(randn(n, n), :U) # build from the upper triangular part1000×1000 Symmetric{Float64, Matrix{Float64}}:
-0.387613 0.830797 0.731869 … 0.0438502 0.39227 -1.73985
0.830797 0.798861 -1.2226 -0.152364 0.348436 -1.53224
0.731869 -1.2226 0.712162 0.338267 -0.406531 0.303491
1.63481 2.28494 -0.688582 0.924935 0.814725 1.21108
-1.83127 0.809969 0.0938082 -1.18017 0.800359 -0.555267
0.911476 0.532963 0.0581193 … 0.798043 1.92928 0.653282
-1.08284 -0.39067 -1.93781 0.560661 -0.857352 -1.49901
1.61787 1.98693 -0.766486 -0.622425 -1.16277 2.00806
1.77062 0.0125561 -0.708909 -1.27664 -1.51582 0.189037
-0.365245 0.665422 0.659153 0.310974 0.69347 -0.328191
-0.331965 0.925945 0.237316 … -0.740832 0.535047 1.46116
-0.697962 -1.16414 1.78832 -0.107645 1.23204 1.10244
-0.2055 -0.350213 0.730864 -1.50582 1.28053 0.185578
⋮ ⋱
-1.33994 -0.207696 0.276488 0.0702686 0.474359 -1.90014
-0.0506158 0.381956 1.2497 2.45185 -0.577832 -0.087702
0.486985 1.5383 -0.890526 … 0.477043 -2.06086 0.745614
-1.07223 1.14012 0.969375 -0.591605 0.907349 -0.0105815
1.46845 0.981375 -1.36146 -0.742225 1.39159 1.26403
-0.113087 0.261022 -0.0422322 -0.0115979 -0.666856 0.657904
2.41368 1.2471 -0.908807 -0.59915 1.58512 1.93124
1.49221 -0.00478031 1.01257 … 2.18865 -0.144515 0.108744
0.217292 0.023727 -0.937259 1.05869 0.537121 1.02429
0.0438502 -0.152364 0.338267 -0.466739 -0.648593 -0.24912
0.39227 0.348436 -0.406531 -0.648593 2.51402 0.582001
-1.73985 -1.53224 0.303491 -0.24912 0.582001 -2.29198BenchmarkTools.Trial: 102 samples with 1 evaluation. Range (min … max): 41.617 ms … 70.308 ms ┊ GC (min … max): 0.00% … 6.26% Time (median): 48.271 ms ┊ GC (median): 0.00% Time (mean ± σ): 49.115 ms ± 5.018 ms ┊ GC (mean ± σ): 1.41% ± 2.83% ▃▁ ▃ ▁ ▁ ▃█ ▆ ▁ ▄▁██▆█▇█▆█▇▆▆██▇▇█▄▇▇▄▆▇█▆▆▇▆▇▁▆▁▆▄▄▁▄▁▁▁▁▁▁▁▁▁▁▁▁▁▄▁▁▁▁▁▁▄ ▄ 41.6 ms Histogram: frequency by time 67.1 ms < Memory estimate: 7.99 MiB, allocs estimate: 11.
BenchmarkTools.Trial: 27 samples with 1 evaluation. Range (min … max): 176.221 ms … 213.026 ms ┊ GC (min … max): 0.00% … 1.51% Time (median): 186.644 ms ┊ GC (median): 0.00% Time (mean ± σ): 190.981 ms ± 13.316 ms ┊ GC (mean ± σ): 0.74% ± 0.80% █ █ ▃ █▇▇▇▇█▁▁▁▁▁▁▁▁▇▇▇▇▁▁▇▇▇▁▁▁▁▁▇▁▁▁▁▁▁▁▁▁▁▁▁▇▁▇▁▁▁▁▇▇▁▁▁▁▇▁▇▁▁▇█ ▁ 176 ms Histogram: frequency by time 213 ms < Memory estimate: 23.25 MiB, allocs estimate: 13.
BenchmarkTools.Trial: 27 samples with 1 evaluation. Range (min … max): 174.911 ms … 339.120 ms ┊ GC (min … max): 0.00% … 1.17% Time (median): 179.500 ms ┊ GC (median): 0.00% Time (mean ± σ): 188.660 ms ± 32.140 ms ┊ GC (mean ± σ): 0.76% ± 0.81% █▆▁ ███▆▁▇▄▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▄▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▄ ▁ 175 ms Histogram: frequency by time 339 ms < Memory estimate: 23.25 MiB, allocs estimate: 13.
Algorithm for SVD
Assume \(\mathbf{A} \in \mathbb{R}^{m \times n}\) and we seek the SVD \(\mathbf{A} = \mathbf{U} \mathbf{D} \mathbf{V}^T\).
Golub-Kahan-Reinsch algorithm
- Stage 1: Transform \(\mathbf{A}\) to an upper bidiagonal form \(\mathbf{B}\) (by Householder).
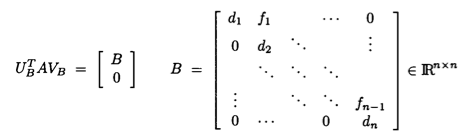
Bidiagonalization
Bidiagonalization 2
Stage 2: Apply implicit shifted QR iteration to the tridiagonal matrix \(\mathbf{B}^T\mathbf{B}\) without explicitly forming it. That is, \(\mathbf{B}^{(t)}\) is directly formed from \(\mathbf{B}^{(t-1)}\).
\(4m^2 n + 8mn^2 + 9n^3\) flops for a tall \((m \ge n)\) matrix.
Example
Julia functions: svd, svd!, svdvals, svdvals!.
SVD{Float64, Float64, Matrix{Float64}, Vector{Float64}}
U factor:
5×3 Matrix{Float64}:
-0.380998 0.214814 -0.38012
0.0761273 0.570332 -0.1334
-0.0902045 -0.577001 -0.736322
0.343699 0.498341 -0.543378
0.850164 -0.217489 -0.0168563
singular values:
3-element Vector{Float64}:
2.772161439329863
1.5236100184747268
1.1153222145932091
Vt factor:
3×3 Matrix{Float64}:
0.134368 0.750489 0.647079
-0.975601 -0.0142296 0.21909
-0.173633 0.66073 -0.7302665×3 Matrix{Float64}:
-0.380998 0.214814 -0.38012
0.0761273 0.570332 -0.1334
-0.0902045 -0.577001 -0.736322
0.343699 0.498341 -0.543378
0.850164 -0.217489 -0.01685633×3 Matrix{Float64}:
0.134368 0.750489 0.647079
-0.975601 -0.0142296 0.21909
-0.173633 0.66073 -0.7302663×3 adjoint(::Matrix{Float64}) with eltype Float64:
0.134368 -0.975601 -0.173633
0.750489 -0.0142296 0.66073
0.647079 0.21909 -0.730266Don’t request singular vectors unless needed.
BenchmarkTools.Trial: 127 samples with 1 evaluation. Range (min … max): 35.415 ms … 49.818 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 38.556 ms ┊ GC (median): 0.00% Time (mean ± σ): 39.411 ms ± 3.157 ms ┊ GC (mean ± σ): 0.97% ± 2.85% ▁ ▃▄▃▃▃ ▁▄ █▃▃▃▁ ▁ ▁ ▁ █▇▄█████▆▆▆██▇█████▆▆█▆▆▆▆▄▁▁▁▁▁▆▆▁▁▄▁▄█▄▆▄█▄▄▁▁▄▁▆▁▄▆▄▄▁▁▄ ▄ 35.4 ms Histogram: frequency by time 47.2 ms < Memory estimate: 4.11 MiB, allocs estimate: 9.
BenchmarkTools.Trial: 59 samples with 1 evaluation. Range (min … max): 72.871 ms … 103.514 ms ┊ GC (min … max): 0.00% … 3.23% Time (median): 82.671 ms ┊ GC (median): 0.00% Time (mean ± σ): 86.051 ms ± 9.452 ms ┊ GC (mean ± σ): 1.44% ± 1.89% ▁ ▁ ▁ ▄▄ ▄▁▁▁ █ █ ▁ ▁ ▁ ▁▁▁ █▁█▁▆▁▆▆█▁▆██▆████▆█▆█▆▆▆█▁▁▁▁▁▁▁▁▁▁▁▁▁▆▁▁▁▆▁▁▆▆▁█▆▁█▁▁▆▆███ ▁ 72.9 ms Histogram: frequency by time 103 ms < Memory estimate: 17.23 MiB, allocs estimate: 12.
Jacobi’s method for symmetric EVD
- One of the oldest ideas for computing eigenvalues, by Jacobi in 1845.
Assume \(\mathbf{A} \in \mathbf{R}^{n \times n}\) is symmetric and we seek the EVD of \(\mathbf{A} = \mathbf{U} \Lambda \mathbf{U}^T\).
- Idea: diagonalize a 2x2 matrix by similarity transform using an orthogonal matrix:
\[ \small \begin{bmatrix} c & -s \\ s & c \end{bmatrix} \begin{bmatrix} a & d \\ d & b \end{bmatrix} \begin{bmatrix} c & s \\ -s & c \end{bmatrix} = \begin{bmatrix} * & 0 \\ 0 & * \end{bmatrix} \]
It can be easily seen that \(c=\cos\theta\) and \(s=\sin\theta\) satisifies \[ \small \tan(2\theta) = \frac{2d}{b-a} \] if \(a\neq b\), otherwise \(c=s=1/\sqrt{2}\).
- We can systematically reduce off-diagonal entries of \(\mathbf{A}\) \[ \small \text{off}(\mathbf{A}) = \sum_i \sum_{j \ne i} a_{ij}^2 \] by Jacobi/Givens rotations: \[ \small \begin{eqnarray*} \mathbf{J}(p,q,\theta) = \begin{bmatrix} 1 & & 0 & & 0 & & 0 \\ \vdots & \ddots & \vdots & & \vdots & & \vdots \\ 0 & & \cos(\theta) & & \sin(\theta) & & 0 \\ \vdots & & \vdots & \ddots & \vdots & & \vdots \\ 0 & & - \sin(\theta) & & \cos(\theta) & & 0 \\ \vdots & & \vdots & & \vdots & \ddots & \vdots \\ 0 & & 0 & & 0 & & 1 \end{bmatrix} . \end{eqnarray*} \] \(\mathbf{J}(p,q,\theta)\) is orthogonal.
Consider \(\mathbf{B} = \mathbf{J}^T \mathbf{A} \mathbf{J}\). \(\mathbf{B}\) preserves the symmetry and eigenvalues of \(\mathbf{A}\). Taking \[ \small \begin{eqnarray*} \begin{cases} \tan (2\theta) = 2a_{pq}/({a_{qq}-a_{pp}}) & \text{if } a_{pp} \ne a_{qq} \\ \theta = \pi/4 & \text{if } a_{pp}=a_{qq} \end{cases} \end{eqnarray*} \] forces \(b_{pq}=0\).
Since orthogonal transform preserves Frobenius norm, we have \[ \small b_{pp}^2 + b_{qq}^2 = a_{pp}^2 + a_{qq}^2 + 2a_{pq}^2. \]
Since \(\|\mathbf{A}\|_{\text{F}} = \|\mathbf{B}\|_{\text{F}}\), \[ \small \begin{split} \|\mathbf{B}\|_{\text{F}}^2 &= \text{off}(\mathbf{B}) + \|\text{diag}(B)\|_2^2 \\ &= \text{off}(\mathbf{B}) + \|\text{diag}(A)\|_2^2 + 2a_{pq}^2 &= \text{off}(\mathbf{A}) + \|\text{diag}(A)\|_2^2 &= \|\mathbf{A}\|_{\text{F}}^2 \end{split} \] or \[ \small \text{off}(\mathbf{B}) = \text{off}(\mathbf{A}) - 2a_{pq}^2 < \text{off}(\mathbf{A}) \] whenever \(a_{pq} \ne 0\).
One Jacobi rotation costs \(O(n)\) flops.
Classical Jacobi: search for the largest \(|a_{ij}|\) at each iteration. \(O(n^2)\) efforts!
\(\text{off}(\mathbf{A}) \le n(n-1) a_{ij}^2\) and \(\text{off}(\mathbf{B}) = \text{off}(\mathbf{A}) - 2 a_{ij}^2\) together implies \[ \text{off}(\mathbf{B}) \le \left( 1 - \frac{2}{n(n-1)} \right) \text{off}(\mathbf{A}). \] Thus Jacobi’s method converges at least linearly.
In practice, cyclic-by-row implementation, to avoid the costly \(O(n^2)\) search in the classical Jacobi.
- Jacobi method attracts a lot recent attention because of its rich inherent parallelism (and does not need tridiagonal reduction).
Krylov subspace methods for top eigen-pairs
State-of-art iterative methods for obtaining the top eigenvalues/vectors or singular values/vectors of large sparse or structured matrices.
Recall the PageRank problem. We want to find the top left eigenvector of the transition matrix \(\mathbf{P}\) of size \(10^9\) by \(10^9\). Direct methods such as (unsymmetric) QR or SVD takes forever. Iterative methods such as power method is feasible. However power method may take a large number of iterations.
Motivation
Recall the Rayleigh quotient \[ r(\mathbf{x}) = \frac{\mathbf{x}^T\mathbf{A}\mathbf{x}}{\mathbf{x}^T\mathbf{x}} \]
Note \(r(\mathbf{u}_i) = \lambda_i\).
Suppose \(\mathbf{q}_1, \dotsc, \mathbf{q}_n\) form an orthonormal basis of \(\mathbb{R}^n\). Define \[ M_k \triangleq \max_{\mathbf{u}\in\text{span}(\mathbf{q}_1,\dotsc,\mathbf{q}_k)} r(\mathbf{u}), \quad \text{and} \quad m_k \triangleq \min_{\mathbf{v}\in\text{span}(\mathbf{q}_1,\dotsc,\mathbf{q}_k)} r(\mathbf{v}). \]
Obviously \[ \begin{split} M_1 &\le M_2 \le \dotsb \le M_n = \lambda_1, \\ m_1 &\ge m_2 \ge \dotsb \ge m_n = \lambda_n. \end{split} \]
The goal is to choose \(\mathbf{q}_1, \mathbf{q}_2, \dotsc\) so that \(M_k \approx \lambda_1\).
Consider the gradient of the Rayleigh quotient: \[ \nabla r(\mathbf{x}) = \frac{2}{\mathbf{x}^T\mathbf{x}}(\mathbf{A}\mathbf{x} - r(\mathbf{x})\mathbf{x}). \]
Suppose \(M_k = r(\mathbf{v}_k)\) for some \(\mathbf{v}_k \in \text{span}(\mathbf{q}_1,\dotsc,\mathbf{q}_k)\). If \(\nabla r(\mathbf{v}_k) = 0\), we are done. Otherwise, it is reasonable to choose the next vector \(\mathbf{q}_{k+1}\) so that \[ \nabla r(\mathbf{v}_k) \in \text{span}(\mathbf{q}_1,\dotsc,\mathbf{q}_k, \mathbf{q}_{k+1}) \] because \(r(\mathbf{x})\) increases steepest in this direction.
Since \(\nabla r(\mathbf{v}_k) \in \text{span}(\mathbf{x}, \mathbf{A}\mathbf{x})\), the above proposal is satisfied if \[ \text{span}(\mathbf{q}_1,\dotsc,\mathbf{q}_k) = \text{span}(\mathbf{q}_1, \mathbf{A}\mathbf{q}_1, \dotsc, \mathbf{A}^{k-1}\mathbf{q}_1) = \mathcal{K}^k(\mathbf{A}, \mathbf{q}_1). \]
Finding \(\mathbf{q}_1, \mathbf{q}_2, \dotsc\) amounts to computing orthonormal bases for \(\mathcal{K}^k(\mathbf{A}, \mathbf{q}_1)\) (Gram-Schmidt).
The eigenvalues of the \(k\times k\) matrix \(\mathbf{Q}_k^T\mathbf{A}\mathbf{Q}_k\) (either tridiagonal or upper Hessenberg), call the Ritz values, approximate the top \(k\) eigenvalues of \(\mathbf{A}\).
Instances
Lanczos method: top eigen-pairs of a large symmetric matrix. (Use tridiagonal reduction \(\mathbf{Q}^T\mathbf{A}\mathbf{Q} = \mathbf{T}\).)
Arnoldi method: top eigen-pairs of a large asymmetric matrix. (Use Hessenberg reduction \(\mathbf{Q}^T\mathbf{A}\mathbf{Q} = \mathbf{H}\).)
Both methods are also adapted to obtain top singular values/vectors of large sparse or structured matrices.
eigsandsvdsin Julia Arpack.jl package and Matlab are wrappers of the ARPACK package, which implements Lanczos and Arnoldi methods.
using MatrixDepot, SparseArrays
# Download the Boeing/bcsstk34 matrix (sparse, pd, 588-by-588) from SuiteSparse collection
# https://sparse.tamu.edu/Boeing
A = matrixdepot("Boeing/bcsstk34")
# Change type of A from Symmetric{Float64,SparseMatrixCSC{Float64,Int64}} to SparseMatrixCSC
A = sparse(A)
@show typeof(A)
Afull = Matrix(A)
@show typeof(Afull)
# actual sparsity level
count(!iszero, A) / length(A)typeof(A) = SparseMatrixCSC{Float64, Int64}
typeof(Afull) = Matrix{Float64}0.06194756814290342┌──────────────────────────────────────────┐ 1 │⡿⣯⣭⠛⠳⢶⣀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ > 0 │⣧⠛⠿⣧⣄⠐⠿⣿⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ < 0 │⢹⣆⢀⠙⢿⣷⢀⣠⡝⣿⡆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠸⣿⣧⠀⣰⣿⣿⣦⢀⣿⣿⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠈⠻⣷⣭⠈⢛⡻⣮⡅⠙⣻⣿⣦⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠈⠉⣿⣿⣅⠉⣿⣿⣍⠁⢹⣿⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠈⠻⣿⣾⠇⠙⣿⣿⣶⠙⢿⣿⣦⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠈⠛⣷⣶⣜⠛⢻⣶⣤⡛⢻⣶⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⣿⣷⣤⠻⣿⣿⣄⠙⢿⣿⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠛⢻⣶⣄⠙⢻⣶⣦⠙⠛⣷⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⣿⣷⣌⠛⢿⣷⣤⡙⢿⣿⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⢿⣤⣄⠻⠿⣧⣄⠙⠿⣧⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⣿⣷⣄⠙⣿⣿⣦⠙⢿⣿⣦⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⠿⣧⣌⠛⠿⣧⣤⡙⠿⢿⣤⡀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠻⣿⣷⣄⠻⣿⣿⣄⠘⢿⣿⣦⡀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⣿⣇⣀⠙⣿⣿⣀⠙⢿⣿⣀⣀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠻⣿⣷⣄⠘⢿⣷⣤⡀⠻⣿⣷⣤⣄⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠻⣿⣷⠀⠻⣿⣿⠀⠀⠙⢿⣿⣷│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⢸⣿⣦⠀⠀⣿⣿⢶⡄⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠙⣿⣷⣄⠘⠷⣿⣿⣦⣠│ 588 │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠙⢿⣿⠀⠀⠈⣻⣿⣿│ └──────────────────────────────────────────┘ ⠀1⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀588⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀21 418 ≠ 0⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
# top 5 eigenvalues by LAPACK (QR algorithm)
n = size(A, 1)
@time eigvals(Symmetric(Afull), (n-4):n) 0.016667 seconds (2.33 k allocations: 2.996 MiB, 35.13% compilation time)5-element Vector{Float64}:
3.4642087294879e7
3.691680883205632e7
3.723096977158153e7
3.725598402633067e7
3.976762941994778e7using Arpack
# top 5 eigenvalues by iterative methods
@time eigs(A; nev=5, ritzvec=false, which=:LM) 2.215533 seconds (3.86 M allocations: 258.556 MiB, 4.99% gc time, 99.79% compilation time)([3.976762941994773e7, 3.725598402633051e7, 3.723096977158146e7, 3.691680883205639e7, 3.464208729487892e7], 5, 7, 101, [62452.22096265024, -319111.3479949276, -83967.9875361371, -96154.42640644909, 7248.436585979588, -65434.48311713214, 73352.37152493223, 98772.82719860655, -28367.39508102584, -27905.75642512194 … 563314.4050039607, 260043.3556216124, 27074.250039000308, 144975.7650049854, -105385.6629031659, 57703.187803609784, 19548.838518629484, -298438.9773246268, 32018.406730532402, -21586.23359059178])BenchmarkTools.Trial: 429 samples with 1 evaluation. Range (min … max): 8.948 ms … 41.729 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 10.437 ms ┊ GC (median): 0.00% Time (mean ± σ): 11.643 ms ± 3.907 ms ┊ GC (mean ± σ): 3.10% ± 8.35% █▆▄ ▄▁██████▇▆▅▆▅▁▄▁▁▅██▆▅▆▁▁▁▁▁▁▄▄▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▄▄▄▄▄▄▄▄▄ ▆ 8.95 ms Histogram: log(frequency) by time 30.9 ms < Memory estimate: 2.85 MiB, allocs estimate: 14.
BenchmarkTools.Trial: 1599 samples with 1 evaluation. Range (min … max): 2.546 ms … 12.305 ms ┊ GC (min … max): 0.00% … 0.00% Time (median): 3.034 ms ┊ GC (median): 0.00% Time (mean ± σ): 3.121 ms ± 499.116 μs ┊ GC (mean ± σ): 0.50% ± 3.44% ▂▄▆███▇▆▄▄▃▃▂▂ ▁ ▅▅███▇▄▁▇███████████████████▆▇█▇▇▆▇▇▁▄▆▄▆▅▄▄▅▅▁▅▅▄▄▄▄▄▁▅▁▁▅ █ 2.55 ms Histogram: log(frequency) by time 4.57 ms < Memory estimate: 146.33 KiB, allocs estimate: 755.
We see >1000 fold speedup in this case.
Further reading
The QR algorithm by Beresford N. Parlett.
Section 8.6 of Matrix Computations by Gene Golub and Charles Van Loan (2013).