시작하기 전에
다음의 패키지가 설치되어 있지 않으면 설치한다.
# install.packages("tidyverse")
# install.packages("mdsr")
# install.packages("lubridate")
# install.packages("Lahman")
library("tidyverse")
library("mdsr")
library("lubridate")
library("Lahman")
sessionInfo()
R version 4.3.3 (2024-02-29)
Platform: x86_64-apple-darwin20 (64-bit)
Running under: macOS Sonoma 14.2.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-x86_64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Asia/Seoul
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] Lahman_11.0-0 mdsr_0.2.7 lubridate_1.9.3 forcats_1.0.0
[5] stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2 readr_2.1.5
[9] tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.0 tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] gtable_0.3.4 jsonlite_1.8.8 compiler_4.3.3 tidyselect_1.2.0
[5] scales_1.3.0 yaml_2.3.8 fastmap_1.1.1 R6_2.5.1
[9] generics_0.1.3 skimr_2.1.5 knitr_1.45 htmlwidgets_1.6.4
[13] munsell_0.5.0 pillar_1.9.0 tzdb_0.4.0 rlang_1.1.3
[17] utf8_1.2.4 stringi_1.8.3 repr_1.1.6 xfun_0.42
[21] timechange_0.3.0 cli_3.6.2 withr_3.0.0 magrittr_2.0.3
[25] digest_0.6.34 grid_4.3.3 rstudioapi_0.15.0 base64enc_0.1-3
[29] hms_1.1.3 lifecycle_1.0.4 vctrs_0.6.5 evaluate_0.23
[33] glue_1.7.0 fansi_1.0.6 colorspace_2.1-0 rmarkdown_2.25
[37] tools_4.3.3 pkgconfig_2.0.3 htmltools_0.5.7
데이터 랭글링을 위한 문법
dplyr
데이터프레임을 다룰 때 사용하는 5개의 (영어) 동사:
select(): 열을 선택 (변수)filter(): 행을 선택 (관측단위)mutate(): 열을 추가하거나 변형arrange(): 행을 정렬summarize(): 여러 행에 걸쳐 데이터 집계
select()
ggplot2에 있는 최근 미국 대통령 정보가 담긴 presidential 데이터 프레임을 사용해 이 함수들의 역할을 알아보자.
library(tidyverse)
library(mdsr)
presidential
# A tibble: 12 × 4
name start end party
<chr> <date> <date> <chr>
1 Eisenhower 1953-01-20 1961-01-20 Republican
2 Kennedy 1961-01-20 1963-11-22 Democratic
3 Johnson 1963-11-22 1969-01-20 Democratic
4 Nixon 1969-01-20 1974-08-09 Republican
5 Ford 1974-08-09 1977-01-20 Republican
6 Carter 1977-01-20 1981-01-20 Democratic
7 Reagan 1981-01-20 1989-01-20 Republican
8 Bush 1989-01-20 1993-01-20 Republican
9 Clinton 1993-01-20 2001-01-20 Democratic
10 Bush 2001-01-20 2009-01-20 Republican
11 Obama 2009-01-20 2017-01-20 Democratic
12 Trump 2017-01-20 2021-01-20 Republican
select() 함수를 사용해 대통령 이름(name)과 소속 정당(party)만 선택
select(presidential, name, party)
# A tibble: 12 × 2
name party
<chr> <chr>
1 Eisenhower Republican
2 Kennedy Democratic
3 Johnson Democratic
4 Nixon Republican
5 Ford Republican
6 Carter Democratic
7 Reagan Republican
8 Bush Republican
9 Clinton Democratic
10 Bush Republican
11 Obama Democratic
12 Trump Republican
filter()함수를 사용해 공화당(Republican) 출신의 대통령들만 선택
filter(presidential, party == "Republican")
# A tibble: 7 × 4
name start end party
<chr> <date> <date> <chr>
1 Eisenhower 1953-01-20 1961-01-20 Republican
2 Nixon 1969-01-20 1974-08-09 Republican
3 Ford 1974-08-09 1977-01-20 Republican
4 Reagan 1981-01-20 1989-01-20 Republican
5 Bush 1989-01-20 1993-01-20 Republican
6 Bush 2001-01-20 2009-01-20 Republican
7 Trump 2017-01-20 2021-01-20 Republican
- 주의:
== 대신 =를 사용하게 되면, party에 Republican이라는 값을 지정하게 되는 것이 되므로 에러 발생
- 또한
Republican에 따옴표를 꼭 사용하여 이것이 문자열이라는 것을 알려줘야 함
Watergate (1973)
select(
filter(presidential, lubridate::year(start) > 1973 & party == "Democratic"),
name
)
# A tibble: 3 × 1
name
<chr>
1 Carter
2 Clinton
3 Obama
filter() 에서 조건에 맞는 관측단위를 추릴 때
중첩과 파이프
예시 구문에서 filter() 연산은 select() 연산 안에 중첩되어 있음.
5개의 dplyr 동사 각각은 데이터프레임을 입력으로 받고 데이터프레임을 반환하므로 이러한 유형의 중첩이 가능
해당 코드는 파이프 연산자인 %>% (tidyverse) 또는 |> (> R 4.1.0)를 사용해서 가독성을 높일 수 있다.
presidential %>%
filter(lubridate::year(start) > 1973 & party == "Democratic") %>%
select(name)
# A tibble: 3 × 1
name
<chr>
1 Carter
2 Clinton
3 Obama
- 이와 같은 파이프의 연쇄를 파이프라인이라고 한다.
dataframe |> filter(condition)
위의 표현식은 filter(dataframe, condition)과 동등하나 더 읽기 쉬움.
새로운 열 추가
presidential 데이터프레임에서 각 대통령의 임기를 나타내는 수치형 변수를 계산해서, 데이터프레임의 새로운 열로 추가해보자.
날짜 연산은 lubridate 패키지를 사용해 임기 시작일(start)과 마감일(end)간 간격 (interval()) 동안 경과한 해(dyears())를 계산하는 방식으로 수행
library(lubridate)
my_presidents <- presidential %>%
mutate(term.length = interval(start, end) / dyears(1))
my_presidents
# A tibble: 12 × 5
name start end party term.length
<chr> <date> <date> <chr> <dbl>
1 Eisenhower 1953-01-20 1961-01-20 Republican 8
2 Kennedy 1961-01-20 1963-11-22 Democratic 2.84
3 Johnson 1963-11-22 1969-01-20 Democratic 5.16
4 Nixon 1969-01-20 1974-08-09 Republican 5.55
5 Ford 1974-08-09 1977-01-20 Republican 2.45
6 Carter 1977-01-20 1981-01-20 Democratic 4
7 Reagan 1981-01-20 1989-01-20 Republican 8
8 Bush 1989-01-20 1993-01-20 Republican 4
9 Clinton 1993-01-20 2001-01-20 Democratic 8
10 Bush 2001-01-20 2009-01-20 Republican 8
11 Obama 2009-01-20 2017-01-20 Democratic 8
12 Trump 2017-01-20 2021-01-20 Republican 4
기존 열 변경
mutate() 함수는 기존 열의 데이터를 수정할 때도 사용할 수 있다.
주문: presidential 자료에서 각 대통령이 선출된 연도를 나타내는 변수를 데이터프레임에 추가
(단순하게 생각한) 첫 번째 시도로는 모든 대통령이 취임하기 전 연도에 당선되었다고 가정할 수 있다.
my_presidents <- my_presidents %>%
mutate(elected = year(start) - 1) # overwriting my_president
my_presidents
# A tibble: 12 × 6
name start end party term.length elected
<chr> <date> <date> <chr> <dbl> <dbl>
1 Eisenhower 1953-01-20 1961-01-20 Republican 8 1952
2 Kennedy 1961-01-20 1963-11-22 Democratic 2.84 1960
3 Johnson 1963-11-22 1969-01-20 Democratic 5.16 1962
4 Nixon 1969-01-20 1974-08-09 Republican 5.55 1968
5 Ford 1974-08-09 1977-01-20 Republican 2.45 1973
6 Carter 1977-01-20 1981-01-20 Democratic 4 1976
7 Reagan 1981-01-20 1989-01-20 Republican 8 1980
8 Bush 1989-01-20 1993-01-20 Republican 4 1988
9 Clinton 1993-01-20 2001-01-20 Democratic 8 1992
10 Bush 2001-01-20 2009-01-20 Republican 8 2000
11 Obama 2009-01-20 2017-01-20 Democratic 8 2008
12 Trump 2017-01-20 2021-01-20 Republican 4 2016
- 미국 대통령 선거가 매 4년마다만 열리기 때문에 일부 항목이 잘못됨
- 1962년: 존 F. 케네디 대통령이 1963년에 암살 후 린든 존슨이 승계
- 1974년: 리처드 닉슨 대통령이 1974년에 워터게이트로 사임한 후 제럴드 포드가 승계
- 그러므로 1962년이나 1973년이라는 값 대신에 결측치(
NA)값을 덮어써야 한다.
my_presidents <- my_presidents %>%
mutate(elected = ifelse(elected %in% c(1962, 1973), NA, elected))
my_presidents
# A tibble: 12 × 6
name start end party term.length elected
<chr> <date> <date> <chr> <dbl> <dbl>
1 Eisenhower 1953-01-20 1961-01-20 Republican 8 1952
2 Kennedy 1961-01-20 1963-11-22 Democratic 2.84 1960
3 Johnson 1963-11-22 1969-01-20 Democratic 5.16 NA
4 Nixon 1969-01-20 1974-08-09 Republican 5.55 1968
5 Ford 1974-08-09 1977-01-20 Republican 2.45 NA
6 Carter 1977-01-20 1981-01-20 Democratic 4 1976
7 Reagan 1981-01-20 1989-01-20 Republican 8 1980
8 Bush 1989-01-20 1993-01-20 Republican 4 1988
9 Clinton 1993-01-20 2001-01-20 Democratic 8 1992
10 Bush 2001-01-20 2009-01-20 Republican 8 2000
11 Obama 2009-01-20 2017-01-20 Democratic 8 2008
12 Trump 2017-01-20 2021-01-20 Republican 4 2016
ifelse() 함수를 사용해서, elected 열이 1962년 또는 1973년이면 해당 값을 NA 값으로 덮어쓰고, 그렇지 않으면 현재 값과 동일한 값으로.- 간결함을 위해
%in% 연산자를 사용해 elected 값이 1962년 또는 1973년에 해당하는지 확인
변수 이름 변경
- R에서 함수, 데이터프레임 및 변수 이름에 점(
.)을 사용하는 것은 바람직하지 않다.
- S3 class의 method overloading을 위한 generic function 사용법과 충돌
- 앞서 생성한
term.length 열의 이름을 변경
my_presidents <- my_presidents %>%
rename(term_length = term.length) # snake_case (cf. camelCase)
my_presidents
# A tibble: 12 × 6
name start end party term_length elected
<chr> <date> <date> <chr> <dbl> <dbl>
1 Eisenhower 1953-01-20 1961-01-20 Republican 8 1952
2 Kennedy 1961-01-20 1963-11-22 Democratic 2.84 1960
3 Johnson 1963-11-22 1969-01-20 Democratic 5.16 NA
4 Nixon 1969-01-20 1974-08-09 Republican 5.55 1968
5 Ford 1974-08-09 1977-01-20 Republican 2.45 NA
6 Carter 1977-01-20 1981-01-20 Democratic 4 1976
7 Reagan 1981-01-20 1989-01-20 Republican 8 1980
8 Bush 1989-01-20 1993-01-20 Republican 4 1988
9 Clinton 1993-01-20 2001-01-20 Democratic 8 1992
10 Bush 2001-01-20 2009-01-20 Republican 8 2000
11 Obama 2009-01-20 2017-01-20 Democratic 8 2008
12 Trump 2017-01-20 2021-01-20 Republican 4 2016
mutate()을 위한 벡터연산함수들
벡터를 읽고 같은 길이의 벡터를 결과로 준다.
arrange()
- 함수
sort()는 벡터를 정렬할 수 있지만 데이터프레임은 정렬할 수 없다.
arange()를 사용해 데이터프레임을 정렬할 수 있다.
- 각 대통령의 임기 길이를 기준으로
presidential 데이터프레임을 내림차순으로 정렬
my_presidents %>%
arrange(desc(term_length))
# A tibble: 12 × 6
name start end party term_length elected
<chr> <date> <date> <chr> <dbl> <dbl>
1 Eisenhower 1953-01-20 1961-01-20 Republican 8 1952
2 Reagan 1981-01-20 1989-01-20 Republican 8 1980
3 Clinton 1993-01-20 2001-01-20 Democratic 8 1992
4 Bush 2001-01-20 2009-01-20 Republican 8 2000
5 Obama 2009-01-20 2017-01-20 Democratic 8 2008
6 Nixon 1969-01-20 1974-08-09 Republican 5.55 1968
7 Johnson 1963-11-22 1969-01-20 Democratic 5.16 NA
8 Carter 1977-01-20 1981-01-20 Democratic 4 1976
9 Bush 1989-01-20 1993-01-20 Republican 4 1988
10 Trump 2017-01-20 2021-01-20 Republican 4 2016
11 Kennedy 1961-01-20 1963-11-22 Democratic 2.84 1960
12 Ford 1974-08-09 1977-01-20 Republican 2.45 NA
- 사용법: 데이터프레임, 정렬할 열, 그리고 정렬 방향을 지정 (MS Excel의 Data>Sort와 비슷)
my_presidents %>%
arrange(desc(term_length), party, elected)
# A tibble: 12 × 6
name start end party term_length elected
<chr> <date> <date> <chr> <dbl> <dbl>
1 Clinton 1993-01-20 2001-01-20 Democratic 8 1992
2 Obama 2009-01-20 2017-01-20 Democratic 8 2008
3 Eisenhower 1953-01-20 1961-01-20 Republican 8 1952
4 Reagan 1981-01-20 1989-01-20 Republican 8 1980
5 Bush 2001-01-20 2009-01-20 Republican 8 2000
6 Nixon 1969-01-20 1974-08-09 Republican 5.55 1968
7 Johnson 1963-11-22 1969-01-20 Democratic 5.16 NA
8 Carter 1977-01-20 1981-01-20 Democratic 4 1976
9 Bush 1989-01-20 1993-01-20 Republican 4 1988
10 Trump 2017-01-20 2021-01-20 Republican 4 2016
11 Kennedy 1961-01-20 1963-11-22 Democratic 2.84 1960
12 Ford 1974-08-09 1977-01-20 Republican 2.45 NA
summarize()
- 열 하나(벡터)를 단일값(스칼라)으로 어떻게 축소할지 지정해야 함
my_presidents %>%
summarize(
N = n(),
first_year = min(year(start)),
last_year = max(year(end)),
num_dems = sum(party == "Democratic"),
years = sum(term_length),
avg_term_length = mean(term_length)
)
# A tibble: 1 × 6
N first_year last_year num_dems years avg_term_length
<int> <dbl> <dbl> <int> <dbl> <dbl>
1 12 1953 2021 5 68 5.67
- 첫 번째 인수 = 데이터프레임 (파이프로 대체)
- 이후 인수 = 출력에 나타날 변수 목록
- 출력 변수 = 벡터에 적용되는 축소 연산 (
min(), max(), sum(), mean())
- 함수
n()은 단순히 행의 수를 세는 역할을 하고, 이는 종종 유용하게 사용된다.
summarize()을 위한 벡터연산함수들
벡터를 읽고 하나의 값을 결과로 준다.
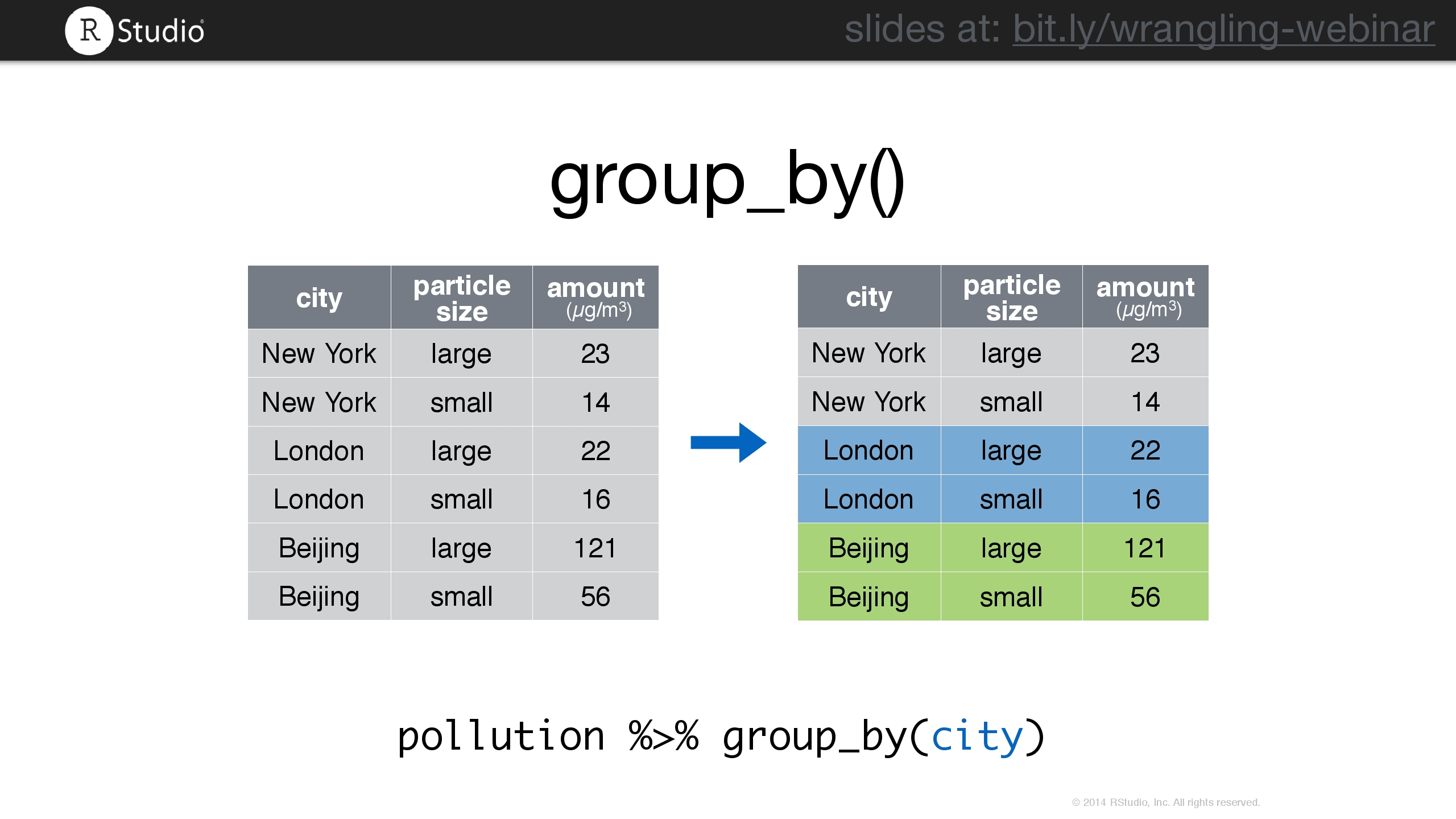
group_by()
민주당 소속 대통령들과 공화당 소속 대통령들 중 어느 쪽이 이 기간 동안 평균 임기가 더 길었는가?
my_presidents 데이터프레임의 행을 party 변수로 묶음
my_presidents %>%
group_by(party) %>%
summarize(
N = n(),
first_year = min(year(start)),
last_year = max(year(end)),
num_dems = sum(party == "Democratic"),
years = sum(term_length),
avg_term_length = mean(term_length)
)
# A tibble: 2 × 7
party N first_year last_year num_dems years avg_term_length
<chr> <int> <dbl> <dbl> <int> <dbl> <dbl>
1 Democratic 5 1961 2017 5 28 5.6
2 Republican 7 1953 2021 0 40 5.71
예제: 야구 데이터 분석
Lahman 패키지
library(Lahman)
dim(Teams)
뉴욕 메츠, 2004–2012
- 세이버메트리션인 Ben Baumer가 뉴욕 메츠에 있었던 2004년부터 2012년까지 팀의 성적을 알아보자.
mets <- Teams %>%
filter(teamID == "NYN")
my_mets <- mets %>%
filter(yearID %in% 2004:2012)
my_mets %>%
select(yearID, teamID, W, L)
yearID teamID W L
1 2004 NYN 71 91
2 2005 NYN 83 79
3 2006 NYN 97 65
4 2007 NYN 88 74
5 2008 NYN 89 73
6 2009 NYN 70 92
7 2010 NYN 79 83
8 2011 NYN 77 85
9 2012 NYN 74 88
- 임시 데이터프레임인
mets와 my_mets를 생성하지 않으면서 같은 작업 수행:
select(filter(Teams, teamID == "NYN" & yearID %in% 2004:2012),
yearID, teamID, W, L)
Teams %>%
filter(teamID == "NYN" & yearID %in% 2004:2012) %>%
select(yearID, teamID, W, L)
yearID teamID W L
1 2004 NYN 71 91
2 2005 NYN 83 79
3 2006 NYN 97 65
4 2007 NYN 88 74
5 2008 NYN 89 73
6 2009 NYN 70 92
7 2010 NYN 79 83
8 2011 NYN 77 85
9 2012 NYN 74 88
추론
- 기술통계량: 2004–2012년간 메츠의 성적
메츠가 부진했던 시즌은 운이 나빴는가, 아니면 실력 부족이었는가?
Bill James의 예상 승률 모형
- 팀이 시즌 전체 동안 득점하고 상대 팀에게 허용한 득점수를 해당 팀이 이길 게임 수의 기대치로 변환 \[
\widehat{WPct}=\frac{1}{1+\left( \frac{RA}{RS} \right)^2}
\]
- \(RA\) = (팀이 상대팀에게 허용한 득점 수), \(RS\) = (팀의 득점 수), \(\widehat{WPct}\) = (팀의 예상 승률)
- \(RA\), \(RS\) 모두
Teams에 있음
mets_ben <- Teams %>%
select(yearID, teamID, W, L, R, RA) %>%
filter(teamID == "NYN" & yearID %in% 2004:2012)
mets_ben
yearID teamID W L R RA
1 2004 NYN 71 91 684 731
2 2005 NYN 83 79 722 648
3 2006 NYN 97 65 834 731
4 2007 NYN 88 74 804 750
5 2008 NYN 89 73 799 715
6 2009 NYN 70 92 671 757
7 2010 NYN 79 83 656 652
8 2011 NYN 77 85 718 742
9 2012 NYN 74 88 650 709
mets_ben <- mets_ben %>%
rename(RS = R) # new name = old name
mets_ben
yearID teamID W L RS RA
1 2004 NYN 71 91 684 731
2 2005 NYN 83 79 722 648
3 2006 NYN 97 65 834 731
4 2007 NYN 88 74 804 750
5 2008 NYN 89 73 799 715
6 2009 NYN 70 92 671 757
7 2010 NYN 79 83 656 652
8 2011 NYN 77 85 718 742
9 2012 NYN 74 88 650 709
mets_ben <- mets_ben %>%
mutate(WPct = W / (W + L))
mets_ben
yearID teamID W L RS RA WPct
1 2004 NYN 71 91 684 731 0.4382716
2 2005 NYN 83 79 722 648 0.5123457
3 2006 NYN 97 65 834 731 0.5987654
4 2007 NYN 88 74 804 750 0.5432099
5 2008 NYN 89 73 799 715 0.5493827
6 2009 NYN 70 92 671 757 0.4320988
7 2010 NYN 79 83 656 652 0.4876543
8 2011 NYN 77 85 718 742 0.4753086
9 2012 NYN 74 88 650 709 0.4567901
mets_ben <- mets_ben %>%
mutate(WPct_hat = 1 / (1 + (RA/RS)^2))
mets_ben
yearID teamID W L RS RA WPct WPct_hat
1 2004 NYN 71 91 684 731 0.4382716 0.4668211
2 2005 NYN 83 79 722 648 0.5123457 0.5538575
3 2006 NYN 97 65 834 731 0.5987654 0.5655308
4 2007 NYN 88 74 804 750 0.5432099 0.5347071
5 2008 NYN 89 73 799 715 0.5493827 0.5553119
6 2009 NYN 70 92 671 757 0.4320988 0.4399936
7 2010 NYN 79 83 656 652 0.4876543 0.5030581
8 2011 NYN 77 85 718 742 0.4753086 0.4835661
9 2012 NYN 74 88 650 709 0.4567901 0.4566674
- (기대 승수) = (예상 승률) x (경기 수)
mets_ben <- mets_ben %>%
mutate(W_hat = WPct_hat * (W + L))
mets_ben
yearID teamID W L RS RA WPct WPct_hat W_hat
1 2004 NYN 71 91 684 731 0.4382716 0.4668211 75.62501
2 2005 NYN 83 79 722 648 0.5123457 0.5538575 89.72491
3 2006 NYN 97 65 834 731 0.5987654 0.5655308 91.61600
4 2007 NYN 88 74 804 750 0.5432099 0.5347071 86.62255
5 2008 NYN 89 73 799 715 0.5493827 0.5553119 89.96053
6 2009 NYN 70 92 671 757 0.4320988 0.4399936 71.27896
7 2010 NYN 79 83 656 652 0.4876543 0.5030581 81.49541
8 2011 NYN 77 85 718 742 0.4753086 0.4835661 78.33771
9 2012 NYN 74 88 650 709 0.4567901 0.4566674 73.98012
- (모형을 믿는다면) 메츠의 운이 세 시즌은 예상보다 좋고, 다른 여섯 시즌 동안 예상보다 나빴음
filter(mets_ben, W >= W_hat)
yearID teamID W L RS RA WPct WPct_hat W_hat
1 2006 NYN 97 65 834 731 0.5987654 0.5655308 91.61600
2 2007 NYN 88 74 804 750 0.5432099 0.5347071 86.62255
3 2012 NYN 74 88 650 709 0.4567901 0.4566674 73.98012
filter(mets_ben, W < W_hat)
yearID teamID W L RS RA WPct WPct_hat W_hat
1 2004 NYN 71 91 684 731 0.4382716 0.4668211 75.62501
2 2005 NYN 83 79 722 648 0.5123457 0.5538575 89.72491
3 2008 NYN 89 73 799 715 0.5493827 0.5553119 89.96053
4 2009 NYN 70 92 671 757 0.4320988 0.4399936 71.27896
5 2010 NYN 79 83 656 652 0.4876543 0.5030581 81.49541
6 2011 NYN 77 85 718 742 0.4753086 0.4835661 78.33771
어떤 시즌이 가장 좋았는가?
arrange(mets_ben, desc(WPct))
yearID teamID W L RS RA WPct WPct_hat W_hat
1 2006 NYN 97 65 834 731 0.5987654 0.5655308 91.61600
2 2008 NYN 89 73 799 715 0.5493827 0.5553119 89.96053
3 2007 NYN 88 74 804 750 0.5432099 0.5347071 86.62255
4 2005 NYN 83 79 722 648 0.5123457 0.5538575 89.72491
5 2010 NYN 79 83 656 652 0.4876543 0.5030581 81.49541
6 2011 NYN 77 85 718 742 0.4753086 0.4835661 78.33771
7 2012 NYN 74 88 650 709 0.4567901 0.4566674 73.98012
8 2004 NYN 71 91 684 731 0.4382716 0.4668211 75.62501
9 2009 NYN 70 92 671 757 0.4320988 0.4399936 71.27896
- 2006년 메츠는 정규 시즌 동안 내셔널리그 최강자로 평가받았으며, 월드시리즈 진출에 아깝게 실패.
- 이런 시즌들은 우리 모형에서 상대적으로 어떻게 순위가 매겨질까?
mets_ben %>%
mutate(Diff = W - W_hat) %>%
arrange(desc(Diff))
yearID teamID W L RS RA WPct WPct_hat W_hat Diff
1 2006 NYN 97 65 834 731 0.5987654 0.5655308 91.61600 5.38400315
2 2007 NYN 88 74 804 750 0.5432099 0.5347071 86.62255 1.37744558
3 2012 NYN 74 88 650 709 0.4567901 0.4566674 73.98012 0.01988152
4 2008 NYN 89 73 799 715 0.5493827 0.5553119 89.96053 -0.96052803
5 2009 NYN 70 92 671 757 0.4320988 0.4399936 71.27896 -1.27895513
6 2011 NYN 77 85 718 742 0.4753086 0.4835661 78.33771 -1.33770571
7 2010 NYN 79 83 656 652 0.4876543 0.5030581 81.49541 -2.49540821
8 2004 NYN 71 91 684 731 0.4382716 0.4668211 75.62501 -4.62501135
9 2005 NYN 83 79 722 648 0.5123457 0.5538575 89.72491 -6.72490937
- 2006년은 메츠의 가장 운이 좋았던 해로 보이며 (모형의 예측보다 5경기 더 이겼음), 2005년은 가장 불운한 해로 보인다 (모형의 예측보다 거의 7경기 적게 이겼음).
- 당연히 어떤 해는 평균에 비해 잘 하고 어떤 해는 못함.
mets_ben %>% mdsr::skim(W)
── Variable type: numeric ──────────────────────────────────────────────────────
var n na mean sd p0 p25 p50 p75 p100
1 W 9 0 80.9 9.10 70 74 79 88 97
- 메츠는 Ben이 일한 9년 동안 평균적으로 거의 81경기를 이겼음을 알 수 있다.
- 162경기로 이루어지는 정규 시즌의 거의 5할 승률에 해당한다.
mets_ben %>%
summarize(
num_years = n(),
total_W = sum(W),
total_L = sum(L),
total_WPct = sum(W) / sum(W + L),
sum_resid = sum(W - W_hat)
)
num_years total_W total_L total_WPct sum_resid
1 9 728 730 0.4993141 -10.64119
층화 분석
- 메츠 단장
- Jim Duquette: 2004
- Omar Minaya: 2005–2010
- Sandy Alderson: 2011–2012
- 단장 재임 시기를 두 개의 중첩된
ifelse() 함수를 사용해 구분
mets_ben <- mets_ben %>%
mutate(
gm = ifelse(
yearID == 2004,
"Duquette",
ifelse(
yearID >= 2011,
"Alderson",
"Minaya")
)
)
- 또는
case_when() 함수를 사용해 더 깔끔하게 표현할 수도 있다.
mets_ben <- mets_ben %>%
mutate(
gm = case_when(
yearID == 2004 ~ "Duquette",
yearID >= 2011 ~ "Alderson",
TRUE ~ "Minaya"
)
)
group_by()
mets_ben %>%
group_by(gm) %>%
summarize(
num_years = n(),
total_W = sum(W),
total_L = sum(L),
total_WPct = sum(W) / sum(W + L),
sum_resid = sum(W - W_hat)
) %>%
arrange(desc(sum_resid))
# A tibble: 3 × 6
gm num_years total_W total_L total_WPct sum_resid
<chr> <int> <int> <int> <dbl> <dbl>
1 Alderson 2 151 173 0.466 -1.32
2 Duquette 1 71 91 0.438 -4.63
3 Minaya 6 506 466 0.521 -4.70
- Minaya 단장 하에서 메츠가 가장 성공적이었지만, 이 세 기간 중 어느 기간에도 기대치를 충족시키지 못했음을 알 수 있다.
파이프라인
Teams %>%
select(yearID, teamID, W, L, R, RA) %>%
filter(teamID == "NYN" & yearID %in% 2004:2012) %>%
rename(RS = R) %>%
mutate(
WPct = W / (W + L),
WPct_hat = 1 / (1 + (RA/RS)^2),
W_hat = WPct_hat * (W + L),
gm = case_when(
yearID == 2004 ~ "Duquette",
yearID >= 2011 ~ "Alderson",
TRUE ~ "Minaya"
)
) %>%
group_by(gm) %>%
summarize(
num_years = n(),
total_W = sum(W),
total_L = sum(L),
total_WPct = sum(W) / sum(W + L),
sum_resid = sum(W - W_hat)
) %>%
arrange(desc(sum_resid))
# A tibble: 3 × 6
gm num_years total_W total_L total_WPct sum_resid
<chr> <int> <int> <int> <dbl> <dbl>
1 Alderson 2 151 173 0.466 -1.32
2 Duquette 1 71 91 0.438 -4.63
3 Minaya 6 506 466 0.521 -4.70
이 9년 동안 다른 팀의 고려했을 때 메츠가 모형에 비해 어떤 성적을 냈는가?
- 3행의
filter()문에서 teamID를 제거, 15행에서 gm 대신 franchID별로 묶음
comptab <- Teams %>%
select(yearID, teamID, franchID, W, L, R, RA) %>%
filter(yearID %in% 2004:2012) %>%
rename(RS = R) %>%
mutate(
WPct = W / (W + L),
WPct_hat = 1 / (1 + (RA/RS)^2),
W_hat = WPct_hat * (W + L)
) %>%
group_by(franchID) %>%
summarize(
num_years = n(),
total_W = sum(W),
total_L = sum(L),
total_WPct = sum(W) / sum(W + L),
sum_resid = sum(W - W_hat)
) %>%
arrange(sum_resid) %>%
head(6);
# A tibble: 6 × 6
franchID num_years total_W total_L total_WPct sum_resid
<fct> <int> <int> <int> <dbl> <dbl>
1 TOR 9 717 740 0.492 -29.2
2 ATL 9 781 677 0.536 -24.0
3 COL 9 687 772 0.471 -22.7
4 CHC 9 706 750 0.485 -14.5
5 CLE 9 710 748 0.487 -13.9
6 NYM 9 728 730 0.499 -10.6
- 모형에 따르면, 메츠보다 더 나쁜 성적을 거둔 팀은 메이저리그 30개 팀 중 다섯 팀뿐임을 알 수 있다.